
Performance analysis of localised large language models in resource-constrained edge for Python and Rust APIs
Article Sidebar
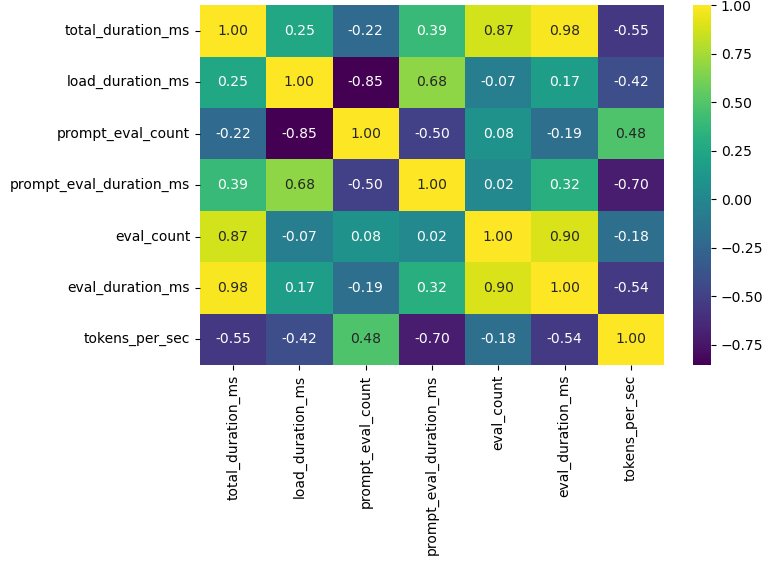
Main Article Content
Abstract
Edge deployments of large language models (LLMs) often suffer from significant latency due to the overhead of high-level client runtimes on resource-constrained hardware. To address this challenge, we conducted a side-by-side performance analysis of four quantised LLMs – Llama 3.2:1b, Gemma 3:1b, Granite 3.1-MoE:1b, and Qwen 2.5:0.5b – on a Raspberry Pi 4 Model B (8 GB LPDDR4, quad-core ARM Cortex-A72) using both Python and Rust API clients. Each model was served via a local Ollama inference server, and a fixed suite of twenty prompts – covering factual retrieval, arithmetic reasoning, translation, code synthesis, and creative generation – was executed sequentially with a two-second inter-request delay, yielding 160 measurements per client. Rust markedly reduces cold-start delays: mean model load times fall from 1 648.7 ms (Python) to 52.8 ms (Rust) for Llama 3.2:1b, and from 607.0 ms to 171.3 ms for Qwen 2.5:0.5b. Corresponding end-to-end latencies decrease by 1.4-2.0 s across models. In warm-start conditions, both clients deliver nearly identical decoding throughput – ≈2.7 tokens/s for Llama 3.2:1b, 4.4 tokens/s for Gemma 3:1b, 7.4 tokens/s for Granite 3.1-MoE, and 8.6 tokens/s for Qwen 2.5:0.5b – indicating that runtime overhead is negligible once models are loaded. Rigorous statistical testing, including paired t-tests, Mann-Whitney U tests, and bootstrap confidence intervals, confirms that Rust’s coldstart advantages are highly significant (p < 0.01). At the same time, throughput differences in steady-state inference are not statistically meaningful. We discuss limitations in platform specificity, quantisation approaches, and prompt diversity, and outline future work on heterogeneous accelerators, adaptive scheduling, and ondevice fine-tuning. Finally, we highlight practical applications in smart agriculture, healthcare monitoring, industrial IoT, autonomous robotics, and offline educational tools. This benchmark furnishes actionable guidelines for selecting client languages and quantised models in edge AI scenarios.
Downloads
Article Details

This work is licensed under a Creative Commons Attribution 4.0 International License.
How to Cite




Accepted 2025-11-25
Published 2026-05-21
References
Abu-Rasheed, H., Jumbo, C., Al Amin, R., Weber, C., Wiese, V., Obermaisser, R. and Fathi, M., 2025. LLM-Assisted Knowledge Graph Completion for Curriculum and Domain Modelling in Personalized Higher Education Recommendations. 2025 IEEE Global Engineering Education Conference (EDUCON). IEEE, pp.1–5. Available from: https://doi.org/10.1109/EDUCON62633.2025.11016377. DOI: https://doi.org/10.1109/EDUCON62633.2025.11016377
Alizadeh, K., Mirzadeh, S.I., Belenko, D., Khatamifard, S., Cho, M., Del Mundo, C.C., Rastegari, M. and Farajtabar, M., 2024. LLM in a flash: Efficient Large Language Model Inference with Limited Memory. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp.12562–12584. Available from: https://aclanthology.org/2024.acl-long.678.pdf. DOI: https://doi.org/10.18653/v1/2024.acl-long.678
Alves, V., Bezerra, C., Machado, I., Rocha, L., Virgínio, T. and Silva, P., 2025. Quality Assessment of Python Tests Generated by Large Language Models. 2506. 14297, Available from: https://doi.org/10.48550/arXiv.2506.14297. DOI: https://doi.org/10.1145/3756681.3756964
Banerjee, D., Singh, P., Avadhanam, A. and Srivastava, S., 2023. Benchmarking LLM powered Chatbots: Methods and Metrics. 2308.04624, Available from: https://doi.org/10.48550/arXiv.2308.04624.
Basu, S., Schillinger, D., Patel, S.Y. and Rigdon, J., 2024. Simulating A/B testing versus SMART designs for LLM-driven patient engagement to close preventive care gaps. npj Digital Medicine, 7(1), p.322. Available from: https://doi.org/10.1038/s41746-024-01330-2. DOI: https://doi.org/10.1038/s41746-024-01330-2
Beierlieb, L., Bauer, A., Leppich, R., Iffländer, L. and Kounev, S., 2023. Efficient Data Processing: Assessing the Performance of Different Programming Languages. Companion of the 2023 ACM/SPEC International Conference on Performance Engineering, ICPE ’23 Companion. pp.83–87. Available from: https://doi.org/10.1145/3578245.3584691. DOI: https://doi.org/10.1145/3578245.3584691
Cheng, X., Sang, F., Zhai, Y., Zhang, X. and Kim, T., 2025. RUG: Turbo LLM for Rust Unit Test Generation. Proceedings of the IEEE/ACM 47th International Conference on Software Engineering. IEEE Computer Society, p.2983–2995. Available from: https://doi.org/10.1109/ICSE55347.2025.00097. DOI: https://doi.org/10.1109/ICSE55347.2025.00097
Chrono: Date and Time for Rust, 2025. Available from: https://docs.rs/chrono.
Chu, B., Feng, Y., Liu, K., Shi, H., Nan, Z., Guo, Z. and Xu, B., 2025. Boosting Rust Unit Test Coverage through Hybrid Program Analysis and Large Language Models. 2506.09002, Available from: https://doi.org/10.48550/arXiv.2506.09002.
Chu, Z., Wang, S., Xie, J., Zhu, T., Yan, Y., Ye, J., Zhong, A., Hu, X., Liang, J., Yu, P.S. and Wen, Q., 2025. LLM Agents for Education: Advances and Applications. 2503.11733, Available from: 10.48550/arXiv.2503.11733. DOI: https://doi.org/10.18653/v1/2025.findings-emnlp.743
CSV – CSV File Reading and Writing, 2025. Available from: https://docs.python.org/3/library/csv.html.
Datetime – Basic date and time types, 2025. Available from: https://docs.python.org/3/library/datetime.html.
Deligiannis, P., Lal, A., Mehrotra, N., Poddar, R. and Rastogi, A., 2024. RustAssistant: Using LLMs to Fix Compilation Errors in Rust Code. Proceedings of the IEEE/ACM 47th International Conference on Software Engineering. IEEE Press, p.3097–3109. Available from: https://doi.org/10.1109/ICSE55347.2025.00022. DOI: https://doi.org/10.1109/ICSE55347.2025.00022
Deligiannis, P., Lal, A., Mehrotra, N. and Rastogi, A., 2023. Fixing Rust Compilation Errors using LLMs. 2308.05177, Available from: https://doi.org/10.48550/arXiv.2308.05177.
Dong, Q., Chen, X. and Satyanarayanan, M., 2024. Creating Edge AI from Cloud-based LLMs. Proceedings of the 25th International Workshop on Mobile Computing Systems and Applications. pp.8–13. Available from: https://doi.org/10.1145/3638550.3641126. DOI: https://doi.org/10.1145/3638550.3641126
Emami, Y., Zhou, H., Nabavirazani, S. and Almeida, L., 2025. LLM-Enabled In-Context Learning for Data Collection Scheduling in UAV-assisted Sensor Networks. 2504.14556, Available from: https://doi.org/10.48550/arXiv.2504.14556.
Eniser, H.F., Zhang, H., David, C., Wang, M., Christakis, M., Paulsen, B., Dodds, J. and Kroening, D., 2024. Towards translating real-world code with LLMs: A study of translating to Rust. 2405.11514, Available from: https://doi.org/10.48550/arXiv.2405.11514.
Gao, H., Yang, Y., Sun, M., Wu, J., Zhou, Y. and Xu, B., 2025. ClozeMaster: Fuzzing Rust Compiler by Harnessing Llms for Infilling Masked Real Programs. Proceedings of the IEEE/ACM 47th International Conference on Software Engineering. IEEE Computer Society, p.1422–1435. Available from: https://doi.org/10.1109/ICSE55347.2025.00175. DOI: https://doi.org/10.1109/ICSE55347.2025.00175
Godoy, W.F., Valero-Lara, P., Teranishi, K., Balaprakash, P. and Vetter, J.S., 2024. Large language model evaluation for high-performance computing software development. Concurrency and Computation: Practice and Experience, 36(26), p.e8269. Available from: https://doi.org/10.1002/cpe.8269. DOI: https://doi.org/10.1002/cpe.8269
Hatalis, K., Christou, D., Myers, J., Jones, S., Lambert, K., Amos-Binks, A., Dannenhauer, Z. and Dannenhauer, D., 2024. Memory Matters: The Need to Improve Long-Term Memory in LLM-Agents. Proceedings of the AAAI Symposium Series, vol. 2. pp.277–280. Available from: https://doi.org/10.1609/aaaiss.v2i1.27688. DOI: https://doi.org/10.1609/aaaiss.v2i1.27688
Hong, J. and Ryu, S., 2025. Type-migrating C-to-Rust translation using a large language model. Empirical Software Engineering, 30(1), p.3. Available from: https://doi.org/10.1007/s10664-024-10573-2. DOI: https://doi.org/10.1007/s10664-024-10573-2
Huey, J.D. and Abdennur, N., 2024. Bigtools: a high-performance BigWig and BigBed library in Rust. Bioinformatics, 40(6), p.btae350. Available from: https://doi.org/10.1093/bioinformatics/btae350. DOI: https://doi.org/10.1093/bioinformatics/btae350
Kao, C.H., Zhao, W., Revankar, S., Speas, S., Bhagat, S., Datta, R., Phoo, C.P., Mall, U., Vondrick, C., Bala, K. and Hariharan, B., 2025. Towards LLM Agents for Earth Observation. 2504.12110, Available from: https://doi.org/10.48550/arXiv.2504.12110.
Lawton, N., Padmakumar, A., Gaspers, J., FitzGerald, J., Kumar, A., Steeg, G.V. and Galstyan, A., 2024. QuAILoRA: Quantization-Aware Initialization for LoRA. 2410.14713, Available from: https://doi.org/10.48550/arXiv.2410.14713.
Li, K. and Yuan, Y., 2024. Large language models as test case generators: Performance evaluation and enhancement. 2404.13340, Available from: https://doi.org/10.48550/arXiv.2404.13340.
Li, Z., Feng, W., Guizani, M. and Yu, H., 2025. TPI-LLM: Serving 70B-scale LLMs Efficiently on Low-resource Mobile Devices. IEEE Transactions on Services Computing, 18(05), pp.3321–3333. Available from: https://doi.org/10.1109/TSC.2025.3596892. DOI: https://doi.org/10.1109/TSC.2025.3596892
Li, Z., Su, Y., Yang, R., Xie, C., Wang, Z., Xie, Z., Wong, N. and Yang, H., 2025. Quantization meets reasoning: Exploring LLM low-bit quantization degradation for mathematical reasoning. 2501.03035, Available from: https://doi.org/10.48550/arXiv.2501.03035.
Liang, L., Gong, J., Liu, M., Wang, C., Ou, G., Wang, Y., Peng, X. and Zheng, Z., 2025. RustEvo2: An Evolving Benchmark for API Evolution in LLM-based Rust Code Generation. 2503.16922, Available from: https://doi.org/10.48550/arXiv.2503.16922.
Lin, J., Tang, J., Tang, H., Yang, S., Xiao, G. and Han, S., 2025. AWQ: Activationaware Weight Quantization for On-Device LLM Compression and Acceleration. GetMobile: Mobile Computing and Communications, 28(4), pp.12–17. Available from: https://doi.org/10.1145/3714983.3714987. DOI: https://doi.org/10.1145/3714983.3714987
Luo, Y., Zhou, H., Zhang, M., De La Rosa, D., Ahmed, H., Xu, W. and Xu, D., 2025. HALURust: Exploiting Hallucinations of Large Language Models to Detect Vulnerabilities in Rust. 2503.10793, Available from: https://doi.org/10.48550/arXiv.2503.10793.
Martins, E.M., Faé, L.G., Hoffmann, R.B., Bianchessi, L.S. and Griebler, D., 2025. NPB-Rust: NAS Parallel Benchmarks in Rust. 2502.15536, Available from: https://doi.org/10.48550/arXiv.2502.15536.
Nitin, V., Krishna, R., Valle, L.L. and Ray, B., 2025. C2SaferRust: Transforming C Projects into Safer Rust with NeuroSymbolic Techniques. 2501.14257, Available from: https://doi.org/10.48550/arXiv.2501.14257. DOI: https://doi.org/10.1109/TSE.2025.3641486
Oh, H., Kim, K., Kim, J., Kim, S., Lee, J., Chang, D.S. and Seo, J., 2024. ExeGPT: Constraint-Aware Resource Scheduling for LLM Inference. Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, vol. 2. pp.369–384. Available from: https://doi.org/10.1145/3620665.3640383. DOI: https://doi.org/10.1145/3620665.3640383
Ollama, 2025. Available from: https://ollama.com/.
OS – Miscellaneous operating system interfaces, 2025. Available from: https://docs.python.org/3/library/os.html.
Park, J.J. and Choi, S.J., 2024. LLMs for Enhanced Agricultural Meteorological Recommendations. 2408.04640, Available from: https://doi.org/10.48550/arXiv.2408.04640.
Prabakar, A. and Kiran, R., 2024. WebAssembly Performance Analysis: A Comparative Study of C++ and Rust Implementations. Available from: https://www.diva-portal.org/smash/get/diva2:1879948/FULLTEXT01.pdf.
Requests: HTTP for Humans™, 2025. Available from: https://requests.readthedocs.io/.
Reqwest, 2025. Available from: https://docs.rs/reqwest/.
Sarhaddi, F., Nguyen, N.T., Zuniga, A., Hui, P., Tarkoma, S., Flores, H. and Nurmi, P., 2025. LLMs and IoT: A Comprehensive Survey on Large Language Models and the Internet of Things. Techrxiv. Available from: https://www.techrxiv.org/doi/full/10.36227/techrxiv.174063060.01215875. DOI: https://doi.org/10.36227/techrxiv.174063060.01215875/v1
Serde, 2025. Available from: https://serde.rs/.
Shetty, M., Jain, N., Godbole, A., Seshia, S.A. and Sen, K., 2024. Syzygy: Dual Code-Test C to (safe) Rust Translation using LLMs and Dynamic Analysis. 2412.14234, Available from: https://doi.org/10.48550/arXiv.2412.14234.
Sinha, S., Kalwani, P., Shah, A. and Gonsalves, J., 2025. High-Performance File Searching with Rust: Parallelized Indexing for Enhanced Computational Efficiency. 2025 IEEE International Conference on Interdisciplinary Approaches in Technology and Management for Social Innovation (IATMSI), vol. 3. IEEE, pp.1–6. Available from: https://doi.org/10.1109/IATMSI64286.2025.10984781. DOI: https://doi.org/10.1109/IATMSI64286.2025.10984781
Time – Time access and conversions, 2025. Available from: https://docs.python.org/3/library/time.html.
Wang, Z., Li, H., Huang, D., Kim, H.S., Shin, C.W. and Rahmani, A.M., 2025. HealthQ: Unveiling questioning capabilities of LLM chains in healthcare conversations. Smart Health, p.100570. Available from: https://doi.org/10.1016/j.smhl.2025.100570. DOI: https://doi.org/10.1016/j.smhl.2025.100570
Wu, J., Chen, S., Cao, J., Lo, H.C. and Cheung, S.C., 2025. Isolating languagecoding from problem-solving: Benchmarking llms with pseudoeval. 2502.19149, Available from: https://doi.org/10.48550/arXiv.2502.19149.
Xia, Y., Fu, F., Zhang, W., Jiang, J. and Cui, B., 2024. Efficient Multi-task LLM Quantization and Serving for Multiple LoRA Adapters. Advances in Neural Information Processing Systems, vol. 37. pp.63686–63714. Available from: https://proceedings.neurips.cc/paper_files/paper/2024/hash/747dc7c6566c74eb9a663bcd8d057c78-Abstract-Conference.html. DOI: https://doi.org/10.52202/079017-2034
Xu, D., Yin, W., Zhang, H., Jin, X., Zhang, Y., Wei, S., Xu, M. and Liu, X., 2025. EdgeLLM: Fast On-device LLM Inference with Speculative Decoding. IEEE Transactions on Mobile Computing, p.3256–3273. Available from: https://doi.org/10.1109/TMC.2024.3513457. DOI: https://doi.org/10.1109/TMC.2024.3513457
Yang, A.Z., Takashima, Y., Paulsen, B., Dodds, J. and Kroening, D., 2024. VERT: Verified Equivalent Rust Transpilation with Large Language Models as Few-Shot Learners. 2404.18852, Available from: https://doi.org/10.48550/arXiv.2404.18852.
Yao, J., Zhou, Z., Chen, W. and Cui, W., 2023. Leveraging Large Language Models for Automated Proof Synthesis in Rust. 2311.03739, Available from: https://doi.org/10.48550/arXiv.2311.03739.
Yu, Z., Wang, Z., Li, Y., Gao, R., Zhou, X., Bommu, S.R., Zhao, Y. and Lin, Y., 2024. EDGE-LLM: Enabling Efficient Large Language Model Adaptation on Edge Devices via Unified Compression and Adaptive Layer Voting. Proceedings of the 61st ACM/IEEE Design Automation Conference. p.327. Available from: https://doi.org/10.1145/3649329.3658473. DOI: https://doi.org/10.1145/3649329.3658473
Zeng, C., Liu, S., Xie, Y., Liu, H., Wang, X., Wei, M., Yang, S., Chen, F. and Mei, X., 2025. ABQ-LLM: arbitrary-bit quantized inference acceleration for large language models. Proceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence and Thirty-Seventh Conference on Innovative Applications of Artificial Intelligence and Fifteenth Symposium on Educational Advances in Artificial Intelligence. p.2487. Available from: https://doi.org/10.1609/aaai.v39i21.34385. DOI: https://doi.org/10.1609/aaai.v39i21.34385
Zhang, H., David, C., Wang, M., Paulsen, B. and Kroening, D., 2025. Scalable, Validated Code Translation of Entire Projects using Large Language Models. Proceedings of the ACM on Programming Languages, 9(PLDI), p.212. Available from: https://doi.org/10.1145/3729315. DOI: https://doi.org/10.1145/3729315
Zhang, X., Liu, J., Xiong, Z., Huang, Y., Xie, G. and Zhang, R., 2024. Edge intelligence optimization for large language model inference with batching and quantization. 2024 IEEE Wireless Communications and Networking Conference (WCNC) - Proceedings. IEEE. Available from: https://doi.org/10.1109/WCNC57260.2024.10571127. DOI: https://doi.org/10.1109/WCNC57260.2024.10571127
Zhang, Y., Liu, Z., Feng, Y. and Xu, B., 2024. Leveraging Large Language Model to Assist Detecting Rust Code Comment Inconsistency. Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. pp.356–366. Available from: https://doi.org/10.1145/3691620.3695010. DOI: https://doi.org/10.1145/3691620.3695010
Zhao, W., Jing, W., Lu, Z. and Wen, X., 2024. Edge and Terminal Cooperation Enabled LLM Deployment Optimization in Wireless Network. 2024 IEEE/CIC International Conference on Communications in China (ICCC Workshops). IEEE, pp.220–225. Available from: https://doi.org/10.1109/ICCCWorkshops62562.2024.10693742. DOI: https://doi.org/10.1109/ICCCWorkshops62562.2024.10693742
Zheng, Z., Ren, X., Xue, F., Luo, Y., Jiang, X. and You, Y., 2023. Response Length Perception and Sequence Scheduling: An LLM-Empowered LLM Inference Pipeline. Advances in Neural Information Processing Systems, vol. 36. pp.65517–65530. Available from: https://proceedings.neurips.cc/paper_files/paper/2023/hash/ce7ff3405c782f761fac7f849b41ae9a-Abstract-Conference.html. DOI: https://doi.org/10.52202/075280-2859