
Edge intelligence unleashed: a survey on deploying large language models in resource-constrained environments
Article Sidebar
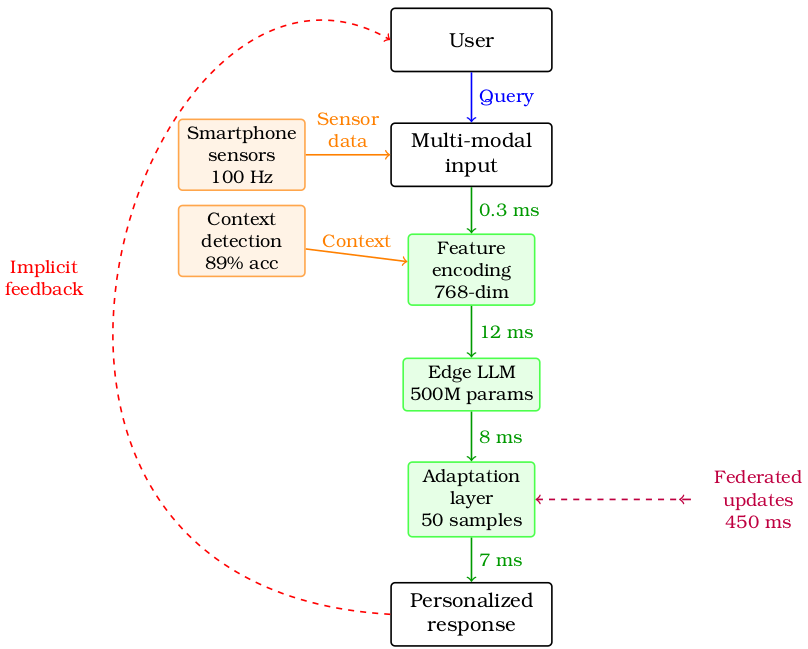
Main Article Content
Abstract
Edge computing environments face unprecedented challenges in deploying large language models due to severe resource constraints, latency requirements, and privacy concerns that traditional cloud-based solutions cannot address. Current approaches struggle with the fundamental mismatch between LLMs' computational demands - requiring gigabytes of memory and billions of operations - and edge devices' limited capabilities, resulting in either degraded performance or infeasible deployments. This survey presents a systematic analysis of emerging techniques that enable efficient LLM deployment at the edge through four complementary strategies: model compression via quantisation and pruning that reduces memory footprint by up to 75% while maintaining accuracy, knowledge distillation frameworks achieving 4000× parameter reduction with comparable performance, edge-cloud collaborative architectures like EdgeShard delivering 50% latency reduction through intelligent workload distribution, and hardware-specific optimisations leveraging specialised accelerators. Extensive evaluation across multiple real-world testbeds demonstrates that hybrid edge-microservices architectures achieve 46% lower P99 latency and 67% higher throughput compared to monolithic approaches, while supporting 10,000 concurrent users with 100 ms latency constraints and reducing bandwidth consumption by 99.5% through selective cloud offloading. These advancements enable transformative applications in healthcare monitoring, autonomous systems, real-time IoT analytics, and personalised AI services, fundamentally reshaping how intelligence is delivered at the network edge while preserving privacy and ensuring responsiveness critical for next-generation computing paradigms.
Downloads
Article Details

This work is licensed under a Creative Commons Attribution 4.0 International License.
How to Cite




Accepted 2025-10-10
Published 2025-11-21
References
Agrawal, R., Kumar, H. and Lnu, S.R., 2025. Efficient LLMs for Edge Devices: Pruning, Quantization, and Distillation Techniques. 2025 International Conference on Machine Learning and Autonomous Systems (ICMLAS). pp.1413–1418. Available from: https://doi.org/10.1109/ICMLAS64557.2025.10968787. DOI: https://doi.org/10.1109/ICMLAS64557.2025.10968787
Ali, M., Aliagha, E., Elnashar, M. and Göhringer, D., 2025. P-CORE: Exploring RISC-V Packed-SIMD Extension for CNNs. IEEE Access, 13, pp.146603–146616. Available from: https://doi.org/10.1109/ACCESS.2025.3600360. DOI: https://doi.org/10.1109/ACCESS.2025.3600360
An, Y., Zhao, X., Yu, T., Tang, M. and Wang, J., 2024. Fluctuation-Based Adaptive Structured Pruning for Large Language Models. Proceedings of the AAAI Conference on Artificial Intelligence, 38(10), pp.10865–10873. Available from: https://doi.org/10.1609/aaai.v38i10.28960. DOI: https://doi.org/10.1609/aaai.v38i10.28960
Armeniakos, G., Maras, A., Xydis, S. and Soudris, D., 2025. Mixed-precision Neural Networks on RISC-V Cores: ISA extensions for Multi-Pumped Soft SIMD Operations. Proceedings of the 43rd IEEE/ACM International Conference on Computer-Aided Design. New York, NY, USA: Association for Computing Machinery, p.235. Available from: https://doi.org/10.1145/3676536.3676840. DOI: https://doi.org/10.1145/3676536.3676840
Arriola, M., Gokaslan, A.K., Chiu, J.T., Yang, Z., Qi, Z., Han, J., Sahoo, S.S. and Kuleshov, V., 2025. Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models. 13th International Conference on Learning Representations, ICLR 2025. pp.84192–84219. Available from: https://openreview.net/forum?id=tyEyYT267x.
Bai, J., Chen, D., Qian, B., Yao, L. and Li, Y., 2025. Federated fine-tuning of large language models under heterogeneous tasks and client resources. Proceedings of the 38th International Conference on Neural Information Processing Systems. Red Hook, NY, USA: Curran Associates Inc., NIPS ’24, p.461.
Bandamudi, L., Singh, R.K., Kunde, S., Mishra, M. and Singhal, R., 2024. LLaMPS: Large Language Models Placement System. Companion of the 15th ACM/SPEC International Conference on Performance Engineering. New York, NY, USA: Association for Computing Machinery, ICPE ’24 Companion, p.87–88. Available from: https://doi.org/10.1145/3629527.3651404. DOI: https://doi.org/10.1145/3629527.3651404
Basit, A. and Shafique, M., 2024. TinyDigiClones: A Multi-Modal LLM-Based Framework for Edge-optimized Personalized Avatars. Proceedings of the International Joint Conference on Neural Networks. Institute of Electrical and Electronics Engineers Inc., pp.1–9. Available from: https://doi.org/10.1109/IJCNN60899.2024.10649909. DOI: https://doi.org/10.1109/IJCNN60899.2024.10649909
Bhardwaj, S., Singh, P. and Pandit, M.K., 2024. A Survey on the Integration and Optimization of Large Language Models in Edge Computing Environments. 2024 16th International Conference on Computer and Automation Engineering, ICCAE 2024. Institute of Electrical and Electronics Engineers Inc., pp.168–172. Available from: https://doi.org/10.1109/ICCAE59995.2024.10569285. DOI: https://doi.org/10.1109/ICCAE59995.2024.10569285
Bin Son, S., Kim, J., Cho, C. and Park, S., 2025. Trends in Network Optimization Using Large Language Models. Journal of Korean Institute of Communications and Information Sciences, 50(7), pp.1073–1084. Available from: https://doi.org/10.7840/kics.2025.50.7.1073. DOI: https://doi.org/10.7840/kics.2025.50.7.1073
Bodenham, M. and Kung, J., 2024. Skipformer: Evolving beyond Blocks for Extensively Searching On-Device Language Models with Learnable Attention Window. IEEE Access, 12, pp.124428–124439. Available from: https://doi.org/10.1109/ACCESS.2024.3420232. DOI: https://doi.org/10.1109/ACCESS.2024.3420232
Brown, T.B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D.M., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, A., Sutskever, I. and Amodei, D., 2020. Language Models are Few-Shot Learners. In: H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan and H. Lin, eds. Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual. pp.1877–1901. Available from: https://proceedings.neurips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.html.
Cai, F., Yuan, D., Yang, Z. and Cui, L., 2024. Edge-LLM: A Collaborative Framework for Large Language Model Serving in Edge Computing. In: R.N. Chang, C.K. Chang, Z. Jiang, J. Yang, Z. Jin, M. Sheng, J. Fan, K.K. Fletcher, Q. He, Q. He, C. Ardagna, J. Yang, J. Yin, Z. Wang, A. Beheshti, S. Russo, N. Atukorala, J. Wu, P.S. Yu, H. Ludwig, S. Reiff-Marganiec, E. Zhang, A. Sailer, N. Bena, K. Li, Y. Watanabe, T. Zhao, S. Wang, Z. Tu, Y. Wang and K. Wei, eds. Proceedings of the IEEE International Conference on Web Services, ICWS. Institute of Electrical and Electronics Engineers Inc., pp.799–809. Available from: https://doi.org/10.1109/ICWS62655.2024.00099. DOI: https://doi.org/10.1109/ICWS62655.2024.00099
Candel, A., McKinney, J., Singer, P., Pfeiffer, P., Jeblick, M., Lee, C.M. and Conde, M.V., 2023. H2O Open Ecosystem for State-of-the-art Large Language Models. In: Y. Feng and E. Lefever, eds. EMNLP 2023 - 2023 Conference on Empirical Methods in Natural Language Processing, Proceedings of the System Demonstrations. Association for Computational Linguistics (ACL), pp.82–89. DOI: https://doi.org/10.18653/v1/2023.emnlp-demo.6
Cao, D. and Aref, S., 2026. Enhancing Ultra-Low-Bit Quantization of Large Language Models Through Saliency-Aware Partial Retraining. In: V. Torra, Y. Narukawa and J. Domingo-Ferrer, eds. Modeling Decisions for Artificial Intelligence. Cham: Springer Nature Switzerland, Lecture Notes in Computer Science, vol. 15957, pp.354–383. Available from: https://doi.org/10.1007/978-3-032-00891-6_28. DOI: https://doi.org/10.1007/978-3-032-00891-6_28
Chen, H., Zhang, J., Du, Y., Xiang, S., Yue, Z., Zhang, N., Cai, Y. and Zhang, Z., 2024. Understanding the Potential of FPGA-based Spatial Acceleration for Large Language Model Inference. ACM Transactions on Reconfigurable Technology and Systems, 18(1), p.5. Available from: https://doi.org/10.1145/3656177. DOI: https://doi.org/10.1145/3656177
Chen, K., Zhou, X., Lin, Y., Feng, S., Shen, L. and Wu, P., 2025. A survey on privacy risks and protection in large language models. Journal of King Saud University - Computer and Information Sciences, 37(7), p.163. Available from: https://doi.org/10.1007/s44443-025-00177-1. DOI: https://doi.org/10.1007/s44443-025-00177-1
Chen, Y., Han, Y. and Li, X., 2025. FASTNav: Fine-Tuned Adaptive Small-Language- Models Trained for Multi-Point Robot Navigation. IEEE Robotics and Automation Letters, 10(1), pp.390–397. Available from: https://doi.org/10.1109/LRA.2024.3506280. DOI: https://doi.org/10.1109/LRA.2024.3506280
Chen, Y., Li, R., Yu, X., Zhao, Z. and Zhang, H., 2025. Adaptive layer splitting for wireless large language model inference in edge computing: a model-based reinforcement learning approach. Frontiers of Information Technology and Electronic Engineering, 26(2), pp.278–292. Available from: https://doi.org/10.1631/FITEE.2400468. DOI: https://doi.org/10.1631/FITEE.2400468
Chen, Y., Li, R., Zhao, Z., Peng, C., Wu, J., Hossain, E. and Zhang, H., 2024. NetGPT: An AI-Native Network Architecture for Provisioning Beyond Personalized Generative Services. IEEE Network, 38(6), pp.404–413. Available from: https://doi.org/10.1109/MNET.2024.3376419. DOI: https://doi.org/10.1109/MNET.2024.3376419
Deschenaux, J. and Gulcehre, C., 2025. Beyond Autoregression: Fast LLMs via Self-Distillation Through Time. 13th International Conference on Learning Representations, ICLR 2025. pp.87644–87682. Available from: https://openreview.net/forum?id=uZ5K4HeNwd.
Dettmers, T., Svirschevski, R., Egiazarian, V., Kuznedelev, D., Frantar, E., Ashkboos, S., Borzunov, A., Hoefler, T. and Alistarh, D., 2024. SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression. 12th International Conference on Learning Representations, ICLR 2024. Available from: https://proceedings.iclr.cc/paper_files/paper/2024/file/1787533e171dcc8549cc2eb5a4840eec-Paper-Conference.pdf.
Devlin, J., Chang, M., Lee, K. and Toutanova, K., 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In: J. Burstein, C. Doran and T. Solorio, eds. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Volume 1 (Long and Short Papers). Association for Computational Linguistics, pp.4171–4186. Available from: https://doi.org/10.18653/V1/N19-1423. DOI: https://doi.org/10.18653/v1/N19-1423
Dhar, N., Deng, B., Islam, M.R., Ahmad Nasif, K.F., Zhao, L. and Suo, K., 2024. Activation Sparsity Opportunities for Compressing General Large Language Models. 2024 IEEE International Performance, Computing, and Communications Conference (IPCCC). Available from: https://doi.org/10.1109/IPCCC59868.2024.10850382. DOI: https://doi.org/10.1109/IPCCC59868.2024.10850382
Do, D.T., Shirai, K. and Nguyen, L.M., 2026. WIP: Iterative Post-training Pruning with Weighted Importance Estimation for Large Language Models. In: R. Ichise, ed. Natural Language Processing and Information Systems. Cham: Springer Nature Switzerland, Lecture Notes in Computer Science, vol. 15836, pp.186–200. Available from: https://doi.org/10.1007/978-3-031-97141-9_13. DOI: https://doi.org/10.1007/978-3-031-97141-9_13
Du, C., Wen, Q., Wei, Z. and Zhang, H., 2024. Energy efficient spike transformer accelerator at the edge. Intelligent Marine Technology and Systems, 2(1), p.24. Available from: https://doi.org/10.1007/s44295-024-00040-5. DOI: https://doi.org/10.1007/s44295-024-00040-5
Du, J., Lin, T., Jiang, C., Yang, Q., Bader, C.F. and Han, Z., 2024. Distributed Foundation Models for Multi-Modal Learning in 6G Wireless Networks. IEEE Wireless Communications, 31(3), pp.20–30. Available from: https://doi.org/10.1109/MWC.009.2300501. DOI: https://doi.org/10.1109/MWC.009.2300501
Dubey, P. and Kumar, M., 2025. Integrating Explainable AI with Federated Learning for Next-Generation IoT: A comprehensive review and prospective insights. Computer Science Review, 56, p.100697. Available from: https://doi.org/10.1016/J.COSREV.2024.100697. DOI: https://doi.org/10.1016/j.cosrev.2024.100697
Eccles, B.J., Wong, L. and Varghese, B., 2026. Mosaic: Composite projection pruning for resource-efficient LLMs. Future Generation Computer Systems, 175, p.108056. Available from: https://doi.org/10.1016/j.future.2025.108056. DOI: https://doi.org/10.1016/j.future.2025.108056
Erdogan, L.E., Lee, N., Jha, S., Kim, S., Tabrizi, R., Moon, S., Hooper, C.R.C., Anumanchipalli, G., Keutzer, K. and Gholami, A., 2024. TinyAgent: Function Calling at the Edge. In: D.I. Hernandez Farias, T. Hope and M. Li, eds. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Miami, Florida, USA: Association for Computational Linguistics, pp.80–88. Available from: https://doi.org/10.18653/v1/2024.emnlp-demo.9. DOI: https://doi.org/10.18653/v1/2024.emnlp-demo.9
Fakih, M., Dharmaji, R., Moghaddas, Y., Quiros, G., Ogundare, O. and Al Faruque, M.A., 2024. LLM4PLC: Harnessing Large Language Models for Verifiable Programming of PLCs in Industrial Control Systems. Proceedings of the 46th International Conference on Software Engineering: Software Engineering in Practice. New York, NY, USA: Association for Computing Machinery, ICSE-SEIP’24, p.192–203. Available from: https://doi.org/10.1145/3639477.3639743. DOI: https://doi.org/10.1145/3639477.3639743
Flemings, J., Razaviyayn, M. and Annavaram, M., 2024. Differentially Private Next-Token Prediction of Large Language Models. In: K. Duh, H. Gomez and S. Bethard, eds. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). Mexico City, Mexico: Association for Computational Linguistics, pp.4390–4404. Available from: https://doi.org/10.18653/v1/2024.naacl-long.247. DOI: https://doi.org/10.18653/v1/2024.naacl-long.247
Friha, O., Amine Ferrag, M., Kantarci, B., Cakmak, B., Ozgun, A. and Ghoualmi-Zine, N., 2024. LLM-Based Edge Intelligence: A Comprehensive Survey on Architectures, Applications, Security and Trustworthiness. IEEE Open Journal of the Communications Society, 5, pp.5799–5856. Available from: https://doi.org/10.1109/OJCOMS.2024.3456549. DOI: https://doi.org/10.1109/OJCOMS.2024.3456549
Fu, C., Su, Y., Su, K., Liu, Y., Shi, J., Wu, B., Liu, C., Ishi, C.T. and Ishiguro, H., 2025. HAM-GNN: A hierarchical attention-based multi-dimensional edge graph neural network for dialogue act classification. Expert Syst. Appl., 261, p.125459. Available from: https://doi.org/10.1016/J.ESWA.2024.125459. DOI: https://doi.org/10.1016/j.eswa.2024.125459
Fu, Y., Yu, Z., Li, J., Qian, J., Zhang, Y., Yuan, X., Shi, D., Yakunin, R. and Lin, Y.C., 2024. AmoebaLLM: Constructing Any-Shape Large Language Models for Efficient and Instant Deployment. In: A. Globersons, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J.M. Tomczak and C. Zhang, eds. Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024. Available from: http://papers.nips.cc/paper_files/paper/2024/hash/8f11e548311c7fd3f33596a4d1dd41f0-Abstract-Conference.html.
Gao, Z., Zhang, Z., Guo, Y. and Gong, Y., 2025. Federated Adaptive Fine-Tuning of Large Language Models with Heterogeneous Quantization and LoRA. Proceedings - IEEE INFOCOM. Institute of Electrical and Electronics Engineers Inc. Available from: https://doi.org/10.1109/INFOCOM55648.2025.11044641. DOI: https://doi.org/10.1109/INFOCOM55648.2025.11044641
Geens, R., Shi, M., Symons, A., Fang, C. and Verhelst, M., 2024. Energy Cost Modelling for Optimizing Large Language Model Inference on Hardware Accelerators. In: G. D., G. U., H. T. and H. K., eds. International System on Chip Conference. IEEE Computer Society. Available from: https://doi.org/10.1109/SOCC62300.2024.10737844. DOI: https://doi.org/10.1109/SOCC62300.2024.10737844
Glint, T., Mittal, B., Sharma, S., Ronak, A.Q., Goud, A., Kasture, N., Momin, Z., Krishna, A. and Mekie, J., 2025. AxLaM: Energy-efficient accelerator design for language models for edge computing. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 383(2288), p.20230395. Available from: https://doi.org/10.1098/rsta.2023.0395. DOI: https://doi.org/10.1098/rsta.2023.0395
Gogineni, K., Suvizi, A. and Venkataramani, G., 2025. LLMs on a Budget: System-Level Approaches to Power-Efficient and Scalable Fine-Tuning. IEEE Open Journal of the Computer Society, 6, pp.987–1000. Available from: https://doi.org/10.1109/OJCS.2025.3580498. DOI: https://doi.org/10.1109/OJCS.2025.3580498
Gou, F. and Wu, J., 2024. Optimization of edge server group collaboration architecture strategy in IoT smart cities application. Peer-to-Peer Networking and Applications, 17(5), pp.3110–3132. Available from: https://doi.org/10.1007/s12083-024-01739-2. DOI: https://doi.org/10.1007/s12083-024-01739-2
Graziano, M., Colucci Cante, L. and Di Martino, B., 2025. Deploying Large Language Model on Cloud-Edge Architectures: A Case Study for Conversational Historical Characters. In: L. Barolli, ed. Advanced Information Networking and Applications. Cham: Springer Nature Switzerland, Lecture Notes on Data Engineering and Communications Technologies, vol. 250, pp.196–205. Available from: https://doi.org/10.1007/978-3-031-87778-0_19. DOI: https://doi.org/10.1007/978-3-031-87778-0_19
Guan, Z., Huang, H., Su, Y., Huang, H., Wong, N. and Yu, H., 2024. APTQ: Attention-aware Post-Training Mixed-Precision Quantization for Large Language Models. Proceedings of the 61st ACM/IEEE Design Automation Conference. New York, NY, USA: Association for Computing Machinery, DAC ’24, p.107. Available from: https://doi.org/10.1145/3649329.3658498. DOI: https://doi.org/10.1145/3649329.3658498
Guo, Y., Hao, Z., Shao, J., Zhou, J., Liu, X., Tong, X., Zhang, Y., Chen, Y., Peng, W. and Ma, Z., 2025. PT-BitNet: Scaling up the 1-Bit large language model with post-training quantization. Neural Networks, 191, p.107855. Available from: https://doi.org/10.1016/j.neunet.2025.107855. DOI: https://doi.org/10.1016/j.neunet.2025.107855
Habibi, S. and Ercetin, O., 2025. Edge-LLM Inference With Cost-Aware Layer Allocation and Adaptive Scheduling. IEEE Access, 13, pp.131614–131637. Available from: https://doi.org/10.1109/ACCESS.2025.3592308. DOI: https://doi.org/10.1109/ACCESS.2025.3592308
Han, C., Yang, T., Cui, Z. and Sun, X., 2025. A Privacy-Preserving and Trustworthy Inference Framework for LLM-IoT Integration via Hierarchical Federated Collaborative Computing. IEEE Internet of Things Journal. Available from: https://doi.org/10.1109/JIOT.2025.3583764. DOI: https://doi.org/10.1109/JIOT.2025.3583764
Hanchuk, D.O. and Semerikov, S.O., 2024. Automating machine learning: A meta-synthesis of MLOps tools, frameworks and architectures. In: S.O. Semerikov and A.M. Striuk, eds. Proceedings of the 7th Workshop for Young Scientists in Computer Science & Software Engineering (CS&SE@SW 2024), Virtual Event, Kryvyi Rih, Ukraine, December 27, 2024. CEUR-WS.org, CEUR Workshop Proceedings, vol. 3917, pp.362–414. Available from: https://ceur-ws.org/Vol-3917/paper60.pdf.
Hao, J., Sun, W., Xin, X., Meng, Q., Chen, Z., Ren, P. and Ren, Z., 2024. MEFT: Memory-Efficient Fine-Tuning through Sparse Adapter. In: L.W. Ku, A. Martins and V. Srikumar, eds. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Bangkok, Thailand: Association for Computational Linguistics, pp.2375–2388. Available from: https://doi.org/10.18653/v1/2024.acl-long.129. DOI: https://doi.org/10.18653/v1/2024.acl-long.129
Hao, Z., Jiang, H., Jiang, S., Ren, J. and Cao, T., 2024. Hybrid SLM and LLM for Edge-Cloud Collaborative Inference. Proceedings of the Workshop on Edge and Mobile Foundation Models. New York, NY, USA: Association for Computing Machinery, EdgeFM ’24, p.36–41. Available from: https://doi.org/10.1145/3662006.3662067. DOI: https://doi.org/10.1145/3662006.3662067
He, J., Wu, S., Wen, W., Xue, C.J. and Li, Q., 2024. CHESS: Optimizing LLM Inference via Channel-Wise Thresholding and Selective Sparsification. In: Y. Al-Onaizan, M. Bansal and Y.N. Chen, eds. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. Miami, Florida, USA: Association for Computational Linguistics, pp.18658–18668. Available from: https://doi.org/10.18653/v1/2024.emnlp-main.1038. DOI: https://doi.org/10.18653/v1/2024.emnlp-main.1038
Helmy, M., Khial, N., Yaacoub, E. and Mohamed, A., 2024. OLRAMT-DEC: Online Learning-Based Resource Allocation for AI Model Training in a Device-Edge-Cloud Continuum. 2024 IEEE Global Conference on Artificial Intelligence and Internet of Things (GCAIoT). Available from: https://doi.org/10.1109/GCAIOT63427.2024.10833575. DOI: https://doi.org/10.1109/GCAIoT63427.2024.10833575
Hong, L., Pan, S., Feng, F. and Jiao, C., 2025. Collaborative Communication for Edge LLM Servicing in Adversarial Networks: An MARL-Empowered Stackelberg Game Approach. IEEE Internet of Things Journal, 12(20), pp.41309–41317. Available from: https://doi.org/10.1109/JIOT.2025.3583280. DOI: https://doi.org/10.1109/JIOT.2025.3583280
Hossain, M.S., Hao, Y., Hu, L., Liu, J., Wei, G. and Chen, M., 2024. Immersive Multimedia Service Caching in Edge Cloud with Renewable Energy. ACM Trans. Multim. Comput. Commun. Appl., 20(6), pp.173:1–173:23. Available from: https://doi.org/10.1145/3643818. DOI: https://doi.org/10.1145/3643818
Hu, C., Huang, H., Xu, L., Chen, X., Wang, C., Xu, J., Chen, S., Feng, H., Wang, S., Bao, Y., Sun, N. and Shan, Y., 2025. ShuffleInfer: Disaggregate LLM Inference for Mixed Downstream Workloads. ACM Transactions on Architecture and Code Optimization, 22(2), p.77. Available from: https://doi.org/10.1145/3732941. DOI: https://doi.org/10.1145/3732941
Hu, Y., Wang, Y., Liu, R., Shen, Z. and Lipson, H., 2024. Reconfigurable Robot Identification from Motion Data. IEEE International Conference on Intelligent Robots and Systems. Institute of Electrical and Electronics Engineers Inc., pp.14133–14140. Available from: https://doi.org/10.1109/IROS58592.2024.10801809. DOI: https://doi.org/10.1109/IROS58592.2024.10801809
Huang, H., Meng, T. and Jia, W., 2025. Joint Optimization of Prompt Security and System Performance in Edge-Cloud LLM Systems. IEEE INFOCOM 2025 - IEEE Conference on Computer Communications. Available from: https://doi.org/10.1109/INFOCOM55648.2025.11044720. DOI: https://doi.org/10.1109/INFOCOM55648.2025.11044720
Huang, Y., Song, J., Wang, Z., Zhao, S., Chen, H., Juefei-Xu, F. and Ma, L., 2025. Look Before You Leap: An Exploratory Study of Uncertainty Analysis for Large Language Models. IEEE Transactions on Software Engineering, 51(2), pp.413–429. Available from: https://doi.org/10.1109/TSE.2024.3519464. DOI: https://doi.org/10.1109/TSE.2024.3519464
Ibrahim, M., Wan, Z., Li, H., Panda, P., Krishna, T., Kanerva, P., Chen, Y. and Raychowdhury, A., 2024. Special Session: Neuro-Symbolic Architecture Meets Large Language Models: A Memory-Centric Perspective. Proceedings - 2024 International Conference on Hardware/Software Codesign and System Synthesis, CODES+ISSS 2024. Institute of Electrical and Electronics Engineers Inc., pp.11–20. Available from: https://doi.org/10.1109/CODES-ISSS60120.2024.00012. DOI: https://doi.org/10.1109/CODES-ISSS60120.2024.00012
Jain, A.M. and Jain, A., 2025. Scaling LLM Inference Architectures: A Performance Analysis for Chatbot Applications. 2025 6th International Conference on Artificial Intelligence, Robotics and Control (AIRC). pp.8–16. Available from: https://doi.org/10.1109/AIRC64931.2025.11077484. DOI: https://doi.org/10.1109/AIRC64931.2025.11077484
Jayanth, R., Gupta, N., Kundu, S., Mathaikutty, D.A. and Prasanna, V., 2024. Towards Real-Time LLM Inference on Heterogeneous Edge Platforms. 2024 IEEE 31st International Conference on High Performance Computing, Data and Analytics Workshop (HiPCW). pp.197–198. Available from: https://doi.org/10.1109/HiPCW63042.2024.00076. DOI: https://doi.org/10.1109/HiPCW63042.2024.00076
Ji, S., Zheng, X., Sun, J., Chen, R., Gao, W. and Srivastava, M., 2024. MindGuard: Towards Accessible and Sitgma-free Mental Health First Aid via Edge LLM. Corr, abs/2409.10064. 2409.10064, Available from: https://doi.org/10.48550/ARXIV.2409.10064.
JianHao, Z., Lv, C., Wang, X., Wu, M., Liu, W., Li, T., Ling, Z., Zhang, C., Zheng, X. and Huang, X., 2024. Promoting Data and Model Privacy in Federated Learning through Quantized LoRA. In: Y. Al-Onaizan, M. Bansal and Y.N. Chen, eds. Findings of the Association for Computational Linguistics: EMNLP 2024. Miami, Florida, USA: Association for Computational Linguistics, pp.10501–10512. Available from: https://doi.org/10.18653/v1/2024.findings-emnlp.615. DOI: https://doi.org/10.18653/v1/2024.findings-emnlp.615
Jin, C., Du, T. and Chen, X., 2025. Energy-Efficient Model Decoupling for Personalized Federated Learning on Cloud-Edge Computing Networks. Transactions on Emerging Telecommunications Technologies, 36(7), p.e70203. Available from: https://doi.org/10.1002/ett.70203. DOI: https://doi.org/10.1002/ett.70203
Kawaharazuka, K., Obinata, Y., Kanazawa, N., Okada, K. and Inaba, M., 2023. Robotic Applications of Pre-Trained Vision-Language Models to Various Recognition Behaviors. IEEE-RAS International Conference on Humanoid Robots. IEEE Computer Society, pp.1–8. Available from: https://doi.org/10.1109/Humanoids57100.2023.10375211. DOI: https://doi.org/10.1109/Humanoids57100.2023.10375211
Khalfi, M.F. and Tabbiche, M.N., 2025. GPThingSim: A IoT Simulator Based GPT Models Over an Edge-Cloud Environments. International Journal of Networked and Distributed Computing, 13(1), p.1. Available from: https://doi.org/10.1007/s44227-024-00045-w. DOI: https://doi.org/10.1007/s44227-024-00045-w
Khoshsirat, A., Perin, G. and Rossi, M., 2024. Decentralized LLM inference over edge networks with energy harvesting. Corr, abs/2408.15907. 2408.15907, Available from: https://doi.org/10.48550/ARXIV.2408.15907.
Kim, J., Seo, M. and Nguyen, X.T., 2025. Mixed INT4-INT8 LLM Quantization via Progressive Layerwise Assignment with Dynamic Sensitivity Estimation. 2025 IEEE International Symposium on Circuits and Systems (ISCAS). Available from: https://doi.org/10.1109/ISCAS56072.2025.11043378. DOI: https://doi.org/10.1109/ISCAS56072.2025.11043378
Latif, E., Fang, L., Ma, P. and Zhai, X., 2024. Knowledge Distillation of LLMs for Automatic Scoring of Science Assessments. In: A.M. Olney, I.A. Chounta, Z. Liu, O.C. Santos and I.I. Bittencourt, eds. Artificial Intelligence in Education. Posters and Late Breaking Results, Workshops and Tutorials, Industry and Innovation Tracks, Practitioners, Doctoral Consortium and Blue Sky. Cham: Springer Nature Switzerland, Communications in Computer and Information Science, vol. 2151, pp.166–174. Available from: https://doi.org/10.1007/978-3-031-64312-5_20. DOI: https://doi.org/10.1007/978-3-031-64312-5_20
Lee, K.H., Sim Lai, M., Lim, S.W., Shuang Ru Teh, J., Nizam, S., Nee, Y.K., Keong Koay, E. and Lee, M.S., 2024. Methodologies for Selecting Optimal Hardware for Locally Deployed LLMs Using a Performance, Accuracy and Cost (PAC) Approach. 2024 2nd International Conference on Foundation and Large Language Models (FLLM). pp.362–369. Available from: https://doi.org/10.1109/FLLM63129.2024.10852499. DOI: https://doi.org/10.1109/FLLM63129.2024.10852499
Lenjani, M. and Skadron, K., 2022. Supporting Moderate Data Dependency, Position Dependency, and Divergence in PIM-Based Accelerators. IEEE Micro, 42(1), pp.108–115. Available from: https://doi.org/10.1109/MM.2021.3136189. DOI: https://doi.org/10.1109/MM.2021.3136189
Li, J., Li, T., Shen, G., Zhao, D., Zhang, Q. and Zeng, Y., 2025. Pushing up to the Limit of Memory Bandwidth and Capacity Utilization for Efficient LLM Decoding on Embedded FPGA. 2025 Design, Automation & Test in Europe Conference (DATE). Available from: https://doi.org/10.23919/DATE64628.2025.10993087. DOI: https://doi.org/10.23919/DATE64628.2025.10993087
Li, Q., Shen, Z., Qin, Z., Xie, Y., Zhang, X., Du, T., Cheng, S., Wang, X. and Yin, J., 2024. TransLinkGuard: Safeguarding Transformer Models Against Model Stealing in Edge Deployment. Proceedings of the 32nd ACM International Conference on Multimedia. New York, NY, USA: Association for Computing Machinery, MM ’24, p.3479–3488. Available from: https://doi.org/10.1145/3664647.3680786. DOI: https://doi.org/10.1145/3664647.3680786
Li, Q., Wen, J. and Jin, H., 2024. Governing Open Vocabulary Data Leaks Using an Edge LLM through Programming by Example. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 8(4), p.179. Available from: https://doi.org/10.1145/3699760. DOI: https://doi.org/10.1145/3699760
Li, Y., Gumaste, D., Turkcan, M.K., Ghaderi, J., Zussman, G. and Kostic, Z., 2025. Distributed VLMs: Efficient Vision-Language Processing through Cloud-Edge Collaboration. 2025 IEEE International Conference on Pervasive Computing and Communications Workshops and other Affiliated Events (PerCom Workshops). pp.280–286. Available from: https://doi.org/10.1109/PerComWorkshops65533.2025.00078. DOI: https://doi.org/10.1109/PerComWorkshops65533.2025.00078
Liao, M., Chen, W., Shen, J., Guo, S. and Wan, H., 2025. HMoRA: Making LLMs More Effective with Hierarchical Mixture of LoRA Experts. 13th International Conference on Learning Representations, ICLR 2025. pp.56079–56100. Available from: https://openreview.net/forum?id=lTkHiXeuDl.
Lin, M.G., Wang, J.P., Luo, Y.J. and Wu, A.Y.A., 2024. A 28nm 64.5TOPS/W Sparse Transformer Accelerator with Partial Product-based Speculation and Sparsity-Adaptive Computation. APCCAS and PrimeAsia 2024. pp.664–668. Available from: https://doi.org/10.1109/APCCAS62602.2024.10808854. DOI: https://doi.org/10.1109/APCCAS62602.2024.10808854
Lin, Y., Wang, X., Zhang, Z., Wang, M., Xiao, T. and Zhu, J., 2023. MobileNMT: Enabling Translation in 15MB and 30ms. In: S. Sitaram, B.B. Klebanov and J.D. Williams, eds. Proceedings of the The 61st Annual Meeting of the Association for Computational Linguistics: Industry Track, ACL 2023, Toronto, Canada, July 9-14, 2023. Association for Computational Linguistics, pp.368–378. Available from: https://doi.org/10.18653/V1/2023.ACL-INDUSTRY.36. DOI: https://doi.org/10.18653/v1/2023.acl-industry.36
Lin, Y.J., Chen, K.Y. and Kao, H.Y., 2023. LAD: Layer-Wise Adaptive Distillation for BERT Model Compression. Sensors, 23(3), p.1483. Available from: https://doi.org/10.3390/s23031483. DOI: https://doi.org/10.3390/s23031483
Liu, J., Ponnusamy, P., Cai, T., Guo, H., Kim, Y. and Athiwaratkun, B., 2025. Training-Free Activation Sparsity in Large Language Models. 13th International Conference on Learning Representations, ICLR 2025. pp.28733–28753. Available from: https://openreview.net/forum?id=dGVZwyq5tV.
Liu, Z., Peng, L., Wang, W., Li, K., Zeng, B., Yu, J. and Liu, X., 2025. Accelerating LLM Inference on RISC-V Edge Devices via Vector Extension Optimization. In: D.S. Huang, C. Zhang, Q. Zhang and Y. Pan, eds. Advanced Intelligent Computing Technology and Applications. Singapore: Springer Nature Singapore, Lecture Notes in Computer Science, vol. 15844, pp.515–526. Available from: https://doi.org/10.1007/978-981-96-9869-1_43. DOI: https://doi.org/10.1007/978-981-96-9869-1_43
Lou, S., Ge, S., Yu, J. and Zhang, G., 2025. TinyVision: Distributed Vision-Language Model with Efficiency and Privacy for Edge Deployment. In: D.S. Huang, W. Chen, Y. Pan and H. Chen, eds. Advanced Intelligent Computing Technology and Applications. Singapore: Springer Nature Singapore, Lecture Notes in Computer Science, vol. 15851, pp.175–187. Available from: https://doi.org/10.1007/978-981-96-9849-3_15. DOI: https://doi.org/10.1007/978-981-96-9849-3_15
Lua, E.K., Crowcroft, J., Pias, M., Sharma, R. and Lim, S., 2005. A survey and comparison of peer-to-peer overlay network schemes. IEEE Communications Surveys & Tutorials, 7(2), pp.72–93. Available from: https://doi.org/10.1109/COMST.2005.1610546. DOI: https://doi.org/10.1109/COMST.2005.1610546
Ma, M., Gong, C., Zeng, L. and Yang, Y., 2025. Multi-Tier Multi-Node Scheduling of LLM for Collaborative AI Computing. IEEE INFOCOM 2025 - IEEE Conference on Computer Communications. Available from: https://doi.org/10.1109/INFOCOM55648.2025.11044698. DOI: https://doi.org/10.1109/INFOCOM55648.2025.11044698
Ma, W., Yang, X., Zeng, S., Liu, T., Shen, L., Wang, H., Li, S., Wang, J., Zhang, Y., Guo, H., Li, J., Zhang, Z., Zhu, Z., Ning, X., Ho, T.Y., Dai, G. and Wang, Y., 2025. FMC-LLM: Enabling FPGAs for Efficient Batched Decoding of 70B+ LLMs with a Memory-Centric Streaming Architecture. Proceedings of the 2025 ACM/SIGDA International Symposium on Field Programmable Gate Arrays. New York, NY, USA: Association for Computing Machinery, FPGA ’25, p.55. Available from: https://doi.org/10.1145/3706628.3708863. DOI: https://doi.org/10.1145/3706628.3708863
Ma, Y., Li, H., Zheng, X., Ling, F., Xiao, X., Wang, R., Wen, S., Chao, F. and Ji, R., 2024. AffineQuant: Affine Transformation Quantization for Large Language Models. The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net. Available from: https://openreview.net/forum?id=of2rhALq8l.
Mahr, F., Angeli, G., Sindel, T., Schmidt, K. and Franke, J., 2024. A Reference Architecture for Deploying Large Language Model Applications in Industrial Environments. IEEE International Symposium for Design and Technology of Electronics Packages, SIITME - Conference Proceedings. Institute of Electrical and Electronics Engineers Inc., pp.19–23. Available from: https://doi.org/10.1109/SIITME63973.2024.10814877. DOI: https://doi.org/10.1109/SIITME63973.2024.10814877
Markova, O., Muzyka, I.O., Kuznetsov, D., Kumchenko, Y. and Senko, A., 2024. Enhancing IoT and cyber-physical systems in industry 4.0 through on-premise large language models: real-time data processing, predictive maintenance, and autonomous decision-making. In: M.T.M. Emmerich, V. Lytvyn and V. Vysotska, eds. Proceedings of the Modern Data Science Technologies Workshop (MoDaST-2024), Lviv, Ukraine, May 31 - June 1, 2024. CEUR-WS.org, CEUR Workshop Proceedings, vol. 3723, pp.182–197. Available from: https://ceur-ws.org/Vol-3723/paper10.pdf.
Marripudugala, M., 2024. Real-Time IoT Data Analytics Using Advanced Large Language Model Techniques. 2024 Global Conference on Communications and Information Technologies (GCCIT). Available from: https://doi.org/10.1109/GCCIT63234.2024.10862622. DOI: https://doi.org/10.1109/GCCIT63234.2024.10862622
Mei, Y., Zhuang, Y., Miao, X., Yang, J., Jia, Z. and Vinayak, R., 2025. Helix: Serving Large Language Models over Heterogeneous GPUs and Network via Max-Flow. Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1. New York, NY, USA: Association for Computing Machinery, ASPLOS ’25, p.586–602. Available from: https://doi.org/10.1145/3669940.3707215. DOI: https://doi.org/10.1145/3669940.3707215
Mohiuddin, I. and Almogren, A., 2019. Workload aware VM consolidation method in edge/cloud computing for iot applications. J. Parallel Distributed Comput., 123, pp.204–214. Available from: https://doi.org/10.1016/J.JPDC.2018.09.011. DOI: https://doi.org/10.1016/j.jpdc.2018.09.011
Monteiro, M., Barros, A., Rodrigues, L., Dermeval, D., Bittencourt, I.I., Isotani, S. and Macario, V., 2025. “Small Device, Big Decision:” Comparing Lightweight LLMs’ Computational Performance and Output Quality for AIED Unplugged. In: A.I. Cristea, E. Walker, Y. Lu, O.C. Santos and S. Isotani, eds. Artificial Intelligence in Education. Posters and Late Breaking Results, Workshops and Tutorials, Industry and Innovation Tracks, Practitioners, Doctoral Consortium, Blue Sky, and WideAIED. Cham: Springer Nature Switzerland, Communications in Computer and Information Science, vol. 2592, pp.160–167. Available from: https://doi.org/10.1007/978-3-031-99267-4_20. DOI: https://doi.org/10.1007/978-3-031-99267-4_20
Mukovoz, V., Vakaliuk, T. and Semerikov, S., 2024. Road Sign Recognition Using Convolutional Neural Networks. Information Technology for Education, Science, and Technics. Cham: Springer Nature Switzerland, Lecture Notes on Data Engineering and Communications Technologies, vol. 222, pp.172–188. Available from: https://doi.org/10.1007/978-3-031-71804-5_12. DOI: https://doi.org/10.1007/978-3-031-71804-5_12
Nie, B., Shao, Y. and Wang, Y., 2024. Know-Adapter: Towards Knowledge-Aware Parameter-Efficient Transfer Learning for Few-shot Named Entity Recognition. In: N. Calzolari, M.Y. Kan, V. Hoste, A. Lenci, S. Sakti and N. Xue, eds. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). Torino, Italia: ELRA and ICCL, pp.9777–9786.
Ormazabal, A., Artetxe, M. and Agirre, E., 2023. CombLM: Adapting Black-Box Language Models through Small Fine-Tuned Models. In: H. Bouamor, J. Pino and K. Bali, eds. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Singapore: Association for Computational Linguistics, pp.2961–2974. Available from: https://doi.org/10.18653/v1/2023.emnlp-main.180. DOI: https://doi.org/10.18653/v1/2023.emnlp-main.180
Ouyang, B., Ye, S., Zeng, L., Qian, T., Li, J. and Chen, X., 2024. Pluto and Charon: A Time and Memory Efficient Collaborative Edge AI Framework for Personal LLMs Fine-tuning. Proceedings of the 53rd International Conference on Parallel Processing. New York, NY, USA: Association for Computing Machinery, ICPP ’24, p.762–771. Available from: https://doi.org/10.1145/3673038.3673043. DOI: https://doi.org/10.1145/3673038.3673043
Park, Y., Hyun, J., Kim, H. and Lee, J.W., 2025. DecDEC: A Systems Approach to Advancing Low-Bit LLM Quantization. Proceedings of the 19th USENIX Symposium on Operating Systems Design and Implementation. pp.803–819. Available from: https://www.usenix.org/system/files/osdi25-park-yeonhong.pdf.
Piccialli, F., Chiaro, D., Qi, P., Bellandi, V. and Damiani, E., 2025. Federated and edge learning for large language models. Information Fusion, 117, p.102840. Available from: https://doi.org/10.1016/j.inffus.2024.102840. DOI: https://doi.org/10.1016/j.inffus.2024.102840
Prabhu, K., Radway, R.M., Yu, J., Bartolone, K., Giordano, M., Peddinghaus, F., Urman, Y., Khwa, W.S., Chih, Y.D., Chang, M.F., Mitra, S. and Raina, P., 2025. MINOTAUR: A Posit-Based 0.42–0.50-TOPS/W Edge Transformer Inference and Training Accelerator. IEEE Journal of Solid-State Circuits, 60(4), pp.1311–1323. Available from: https://doi.org/10.1109/JSSC.2025.3545731. DOI: https://doi.org/10.1109/JSSC.2025.3545731
Qiao, D., Ao, X., Liu, Y., Chen, X., Song, F., Qin, Z. and Jin, W., 2025. Tri-AFLLM: Resource-Efficient Adaptive Asynchronous Accelerated Federated LLMs. IEEE Transactions on Circuits and Systems for Video Technology, 35(5), pp.4198–4211. Available from: https://doi.org/10.1109/TCSVT.2024.3519790. DOI: https://doi.org/10.1109/TCSVT.2024.3519790
Qiao, D., Guo, S., Zhao, J., Le, J., Zhou, P., Li, M. and Chen, X., 2025. ASMAFL: Adaptive Staleness-Aware Momentum Asynchronous Federated Learning in Edge Computing. IEEE Transactions on Mobile Computing, 24(4), pp.3390–3406. Available from: https://doi.org/10.1109/TMC.2024.3510135. DOI: https://doi.org/10.1109/TMC.2024.3510135
Qiao, S., Xu, H., Cao, C., Gong, W., Chen, S. and Liu, J., 2025. PrismPrompt: Layering Prompt-Enhanced Cloud-Edge Collaborative Language Model Toward Healthcare. IEEE Network, 39(4), pp.105–111. Available from: https://doi.org/10.1109/MNET.2025.3532857. DOI: https://doi.org/10.1109/MNET.2025.3532857
Qiao, Y., Yu, Z., Zhao, Z., Chen, S., Sun, M., Guo, L., Wu, Q. and Liu, J., 2024. VL-Mamba: Exploring State Space Models for Multimodal Learning. In: M. Rezagholizadeh, P. Passban, S. Samiee, V. Partovi Nia, Y. Cheng, Y. Deng, Q. Liu and B. Chen, eds. Proceedings of The 4th NeurIPS Efficient Natural Language and Speech Processing Workshop. PMLR, Proceedings of Machine Learning Research, vol. 262, pp.102–113. Available from: https://proceedings.mlr.press/v262/qiao24a.html.
Qin, R., Xia, J., Jia, Z., Jiang, M., Abbasi, A., Zhou, P., Hu, J. and Shi, Y., 2024. Enabling On-Device Large Language Model Personalization with Self-Supervised Data Selection and Synthesis. Proceedings of the 61st ACM/IEEE Design Automation Conference. New York, NY, USA: Association for Computing Machinery, DAC ’24. Available from: https://doi.org/10.1145/3649329.3655665. DOI: https://doi.org/10.1145/3649329.3655665
Qin, R., Yan, Z., Zeng, D., Jia, Z., Liu, D., Liu, J., Abbasi, A., Zheng, Z., Cao, N., Ni, K., Xiong, J. and Shi, Y., 2025. Robust Implementation of Retrieval-Augmented Generation on Edge-based Computing-in-Memory Architectures. Proceedings of the 43rd IEEE/ACM International Conference on Computer-Aided Design. New York, NY, USA: Association for Computing Machinery, ICCAD ’24, p.50. Available from: https://doi.org/10.1145/3676536.3676674. DOI: https://doi.org/10.1145/3676536.3676674
Qin, Y., Wang, Y., Zhao, Z., Yang, X., Zhou, Y., Wei, S., Hu, Y. and Yin, S., 2024. MECLA: Memory-Compute-Efficient LLM Accelerator with Scaling Sub-matrix Partition. 2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). pp.1032–1047. Available from: https://doi.org/10.1109/ISCA59077.2024.00079. DOI: https://doi.org/10.1109/ISCA59077.2024.00079
Qu, G., Chen, Q., Wei, W., Lin, Z., Chen, X. and Huang, K., 2025. Mobile Edge Intelligence for Large Language Models: A Contemporary Survey. IEEE Communications Surveys and Tutorials. Available from: https://doi.org/10.1109/COMST.2025.3527641. DOI: https://doi.org/10.1109/COMST.2025.3527641
Qu, W., Zhou, Y., Wu, Y., Xiao, T., Yuan, B., Li, Y. and Zhang, J., 2025. Prompt Inversion Attack Against Collaborative Inference of Large Language Models. 2025 IEEE Symposium on Security and Privacy (SP). pp.1695–1712. Available from: https://doi.org/10.1109/SP61157.2025.00160. DOI: https://doi.org/10.1109/SP61157.2025.00160
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W. and Liu, P.J., 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research, 21(1), pp.5485–5551.
Ray, P.P. and Pradhan, M.P., 2025. DLUSEdge: Dynamic Load–Unload Scheduling for Localized LLMs on Resource-Constrained Edge. KI - Kunstliche Intelligenz. Available from: https://doi.org/10.1007/s13218-025-00895-8. DOI: https://doi.org/10.1007/s13218-025-00895-8
Ray, P.P. and Pradhan, M.P., 2025. P2PLLMEdge: Peer-to-Peer Framework for Localized Large Language Models using CPU only Resource-Constrained Edge. EAI Endorsed Transactions on AI and Robotics, 4. Available from: https://doi.org/10.4108/airo.9292. DOI: https://doi.org/10.36227/techrxiv.175037023.36907385/v1
Ren, Y., Zhang, H., Yu, F.R., Li, W., Zhao, P. and He, Y., 2024. Industrial Internet of Things with Large Language Models (LLMs): An Intelligence-based Reinforcement Learning Approach. IEEE Transactions on Mobile Computing. Available from: https://doi.org/10.1109/TMC.2024.3522130. DOI: https://doi.org/10.1109/TMC.2024.3522130
Rjoub, G., Elmekki, H., Islam, S., Bentahar, J. and Dssouli, R., 2025. A hybrid swarm intelligence approach for optimizing Multimodal Large Language Models deployment in edge-cloud-based Federated Learning environments. Computer Communications, 237, p.108152. Available from: https://doi.org/10.1016/j.comcom.2025.108152. DOI: https://doi.org/10.1016/j.comcom.2025.108152
Rong, Y., Mao, Y., He, X. and Chen, M., 2025. Large-Scale Traffic Flow Forecast with Lightweight LLM in Edge Intelligence. IEEE Internet of Things Magazine, 8(1), pp.12–18. Available from: https://doi.org/10.1109/IOTM.001.2400047. DOI: https://doi.org/10.1109/IOTM.001.2400047
Ruan, J., Gao, J., Xie, M., Xiang, S., Yu, Z., Liu, T., Fu, Y. and Qu, X., 2024. GIST: Improving Parameter Efficient Fine-Tuning via Knowledge Interaction. Proceedings of the 32nd ACM International Conference on Multimedia. New York, NY, USA: Association for Computing Machinery, MM ’24, p.8835–8844. Available from: https://doi.org/10.1145/3664647.3680843. DOI: https://doi.org/10.1145/3664647.3680843
Semerikov, S.O., Vakaliuk, T.A., Kanevska, O.B., Moiseienko, M.V., Donchev, I.I. and Kolhatin, A.O., 2025. LLM on the edge: the new frontier. In: T.A. Vakaliuk and S.O. Semerikov, eds. Proceedings of the 5th Edge Computing Workshop (doors 2025), Zhytomyr, Ukraine, April 4, 2025. CEUR-WS.org, CEUR Workshop Proceedings, vol. 3943, pp.137–161. Available from: https://ceur-ws.org/Vol-3943/paper28.pdf. DOI: https://doi.org/10.55056/jec.987
Shen, X., Dong, P., Lu, L., Kong, Z., Li, Z., Lin, M., Wu, C. and Wang, Y., 2024. Agile-Quant: Activation-Guided Quantization for Faster Inference of LLMs on the Edge. Proceedings of the AAAI Conference on Artificial Intelligence, 38(17), pp.18944–18951. Available from: https://doi.org/10.1609/aaai.v38i17.29860. DOI: https://doi.org/10.1609/aaai.v38i17.29860
Shen, X., Han, Z., Lu, L., Kong, Z., Dong, P., Li, Z., Xie, Y., Wu, C., Leeser, M., Zhao, P., Lin, X. and Wang, Y., 2024. HotaQ: Hardware Oriented Token Adaptive Quantization for Large Language Models. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems. Available from: https://doi.org/10.1109/TCAD.2024.3487781. DOI: https://doi.org/10.1109/TCAD.2024.3487781
Shen, Y., Shao, J., Zhang, X., Lin, Z., Pan, H., Li, D., Zhang, J. and Letaief, K.B., 2024. Large Language Models Empowered Autonomous Edge AI for Connected Intelligence. IEEE Communications Magazine, 62(10), pp.140–146. Available from: https://doi.org/10.1109/MCOM.001.2300550. DOI: https://doi.org/10.1109/MCOM.001.2300550
Shin, J., Yang, H. and Yi, Y., 2025. SparseInfer: Training-free Prediction of Activation Sparsity for Fast LLM Inference. 2025 Design, Automation & Test in Europe Conference (DATE). pp.1–7. Available from: https://doi.org/10.23919/DATE64628.2025.10992997. DOI: https://doi.org/10.23919/DATE64628.2025.10992997
Sikorski, P., Schrader, L., Yu, K., Billadeau, L., Meenakshi, J., Mutharasan, N., Esposito, F., Aliakbarpour, H. and Babaias, M., 2025. Deployment of Large Language Models to Control Mobile Robots at the Edge. 2025 3rd International Conference on Mechatronics, Control and Robotics (ICMCR). pp.19–24. Available from: https://doi.org/10.1109/ICMCR64890.2025.10963303. DOI: https://doi.org/10.1109/ICMCR64890.2025.10963303
Simpson, S.V. and Nagarajan, G., 2021. An edge based trustworthy environment establishment for internet of things: an approach for smart cities. Wireless Networks. Available from: https://doi.org/10.1007/s11276-021-02667-2. DOI: https://doi.org/10.1007/s11276-021-02667-2
Singh, N. and Adhikari, M., 2025. A Hybrid Semi-Asynchronous Federated Learning and Split Learning Strategy in Edge Networks. IEEE Transactions on Network Science and Engineering, 12(2), pp.1429–1439. Available from: https://doi.org/10.1109/TNSE.2025.3530999. DOI: https://doi.org/10.1109/TNSE.2025.3530999
Strubell, E., Ganesh, A. and McCallum, A., 2020. Energy and Policy Considerations for Modern Deep Learning Research. Proceedings of the AAAI Conference on Artificial Intelligence, 34(09), pp.13693–13696. Available from: https://doi.org/10.1609/aaai.v34i09.7123. DOI: https://doi.org/10.1609/aaai.v34i09.7123
Sun, B., Huang, Z., Zhao, H., Xiao, W., Zhang, X., Li, Y. and Lin, W., 2024. Llumnix: Dynamic Scheduling for Large Language Model Serving. Proceedings of the 18th USENIX Symposium on Operating Systems Design and Implementation, OSDI 2024. pp.173–191. Available from: https://www.usenix.org/system/files/osdi24-sun-biao.pdf.
Sun, H., Zhuang, Y., Wei, W., Zhang, C. and Dai, B., 2024. BBox-Adapter: Lightweight Adapting for Black-Box Large Language Models. Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net. Available from: https://openreview.net/forum?id=jdRIaUu3xY.
Tambe, T., Zhang, J., Hooper, C., Jia, T., Whatmough, P.N., Zuckerman, J., Santos, M.C.D., Loscalzo, E.J., Giri, D., Shepard, K., Carloni, L., Rush, A., Brooks, D. and Wei, G.Y., 2023. 22.9 A 12nm 18.1TFLOPs/W Sparse Transformer Processor with Entropy-Based Early Exit, Mixed-Precision Predication and Fine-Grained Power Management. Digest of Technical Papers - IEEE International Solid-State Circuits Conference. Institute of Electrical and Electronics Engineers Inc., vol. 2023-February, pp.342–344. Available from: https://doi.org/10.1109/ISSCC42615.2023.10067817. DOI: https://doi.org/10.1109/ISSCC42615.2023.10067817
Tan, F., Lee, R., Dudziak, Ł., Hu, S.X., Bhattacharya, S., Hospedales, T., Tzimiropoulos, G. and Martinez, B., 2024. MobileQuant: Mobile-friendly Quantization for On-device Language Models. In: Y. Al-Onaizan, M. Bansal and Y.N. Chen, eds. Findings of the Association for Computational Linguistics: EMNLP 2024. Miami, Florida, USA: Association for Computational Linguistics, pp.9761–9771. Available from: https://doi.org/10.18653/v1/2024.findings-emnlp.570. DOI: https://doi.org/10.18653/v1/2024.findings-emnlp.570
Tang, X., Guo, C., Choo, K.K.R. and Liu, Y., 2024. An Efficient and Dynamic Privacy-Preserving Federated Learning System for Edge Computing. IEEE Transactions on Information Forensics and Security, 19, pp.207–220. Available from: https://doi.org/10.1109/TIFS.2023.3320611. DOI: https://doi.org/10.1109/TIFS.2023.3320611
Tian, A.X., Zhao, Y., Yin, C., Zhu, W., Tian, X. and Ge, Y., 2024. FanLoRA: Fantastic LoRAs and Where to Find Them in Large Language Model Fine-tuning. In: F. Dernoncourt, D. Preoţiuc-Pietro and A. Shimorina, eds. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track. Miami, Florida, US: Association for Computational Linguistics, pp.515–528. Available from: https://doi.org/10.18653/v1/2024.emnlp-industry.38. DOI: https://doi.org/10.18653/v1/2024.emnlp-industry.38
Tian, C., Qin, X., Tam, K., Li, L., Wang, Z., Zhao, Y., Zhang, M. and Xu, C., 2025. CLONE: Customizing LLMs for Efficient Latency-Aware Inference at the Edge. Proceedings of the 2025 USENIX Annual Technical Conference. pp.563–585. Available from: https://www.usenix.org/system/files/atc25-tian.pdf.
Tian, Y., Zhang, B., Tu, Z. and Chu, D., 2025. Adapters Selector: Cross-domains and Multi-tasks LoRA Modules Integration Usage Method. In: O. Rambow, L. Wanner, M. Apidianaki, H. Al-Khalifa, B.D. Eugenio and S. Schockaert, eds. Proceedings of the 31st International Conference on Computational Linguistics. Abu Dhabi, UAE: Association for Computational Linguistics, pp.593–605. Available from: https://aclanthology.org/2025.coling-main.40/.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L. and Polosukhin, I., 2017. Attention is All you Need. In: I. Guyon, U. von Luxburg, S. Bengio, H.M. Wallach, R. Fergus, S.V.N. Vishwanathan and R. Garnett, eds. Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA. pp.5998–6008. Available from: https://proceedings.neurips.cc/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html.
Wang, F., Jiang, J., Park, C., Kim, S. and Tang, J., 2025. KaSA: Knowledge-Aware Singular-Value Adaptation of Large Language Models. The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net. Available from: https://openreview.net/forum?id=OQqNieeivq.
Wang, N., Xie, J., Luo, H., Cheng, Q., Wu, J., Jia, M. and Li, L., 2023. Efficient Image Captioning for Edge Devices. In: B. Williams, Y. Chen and J. Neville, eds. Thirty-Seventh AAAI Conference on Artificial Intelligence, AAAI 2023, Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence, IAAI 2023, Thirteenth Symposium on Educational Advances in Artificial Intelligence, EAAI 2023, Washington, DC, USA, February 7-14, 2023. AAAI Press, pp.2608–2616. Available from: https://doi.org/10.1609/AAAI.V37I2.25359. DOI: https://doi.org/10.1609/aaai.v37i2.25359
Wang, R. and Li, P., 2024. Semantic are Beacons: A Semantic Perspective for Unveiling Parameter-Efficient Fine-Tuning in Knowledge Learning. In: L.W. Ku, A. Martins and V. Srikumar, eds. Findings of the Association for Computational Linguistics: ACL 2024. Bangkok, Thailand: Association for Computational Linguistics, pp.9523–9537. Available from: https://doi.org/10.18653/v1/2024.findings-acl.567. DOI: https://doi.org/10.18653/v1/2024.findings-acl.567
Wang, Y., Dong, Y., Guo, S., Yang, Y. and Liao, X., 2020. Latency-Aware Adaptive Video Summarization for Mobile Edge Clouds. IEEE Trans. Multim., 22(5), pp.1193–1207. Available from: https://doi.org/10.1109/TMM.2019.2939753. DOI: https://doi.org/10.1109/TMM.2019.2939753
Wang, Y., Zhong, G., Duan, Y., Cheng, Y., Yin, M. and Yang, R., 2025. Efficient and privacy-preserving deep inference towards cloud–edge collaborative. Applied Soft Computing, 180, p.113381. Available from: https://doi.org/10.1016/j.asoc.2025.113381. DOI: https://doi.org/10.1016/j.asoc.2025.113381
Wang, Z., Yang, J., Qian, X., Xing, S., Jiang, X., Lv, C. and Zhang, S., 2024. MNN-LLM: A Generic Inference Engine for Fast Large Language Model Deployment on Mobile Devices. Proceedings of the 6th ACM International Conference on Multimedia in Asia Workshops. New York, NY, USA: Association for Computing Machinery, MMAsia ’24 Workshops, p.11. Available from: https://doi.org/10.1145/3700410.3702126. DOI: https://doi.org/10.1145/3700410.3702126
Wang, Z., Zhou, Y., Shi, Y. and Letaief, K.B., 2024. Federated Low-Rank Adaptation for Large Language Model Fine-Tuning Over Wireless Networks. GLOBECOM 2024 - 2024 IEEE Global Communications Conference. pp.3063–3068. Available from: https://doi.org/10.1109/GLOBECOM52923.2024.10901572. DOI: https://doi.org/10.1109/GLOBECOM52923.2024.10901572
Wei, X., Zhang, Y., Li, Y., Zhang, X., Gong, R., Guo, J. and Liu, X., 2023. Outlier Suppression+: Accurate quantization of large language models by equivalent and effective shifting and scaling. In: H. Bouamor, J. Pino and K. Bali, eds. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Singapore: Association for Computational Linguistics, pp.1648–1665. Available from: https://doi.org/10.18653/v1/2023.emnlp-main.102. DOI: https://doi.org/10.18653/v1/2023.emnlp-main.102
Wu, L., Zhao, Y., Wang, C., Liu, T. and Wang, H., 2024. A First Look at LLM-powered Smartphones. Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering Workshops. New York, NY, USA: Association for Computing Machinery, ASEW ’24, p.208–217. Available from: https://doi.org/10.1145/3691621.3694952. DOI: https://doi.org/10.1145/3691621.3694952
Wu, Z., Zhi, C., Han, J., Deng, S. and Yin, J., 2025. LLMAppHub: A Large Collection of LLM-based Applications for the Research Community. Proceedings of the 33rd ACM International Conference on the Foundations of Software Engineering. New York, NY, USA: Association for Computing Machinery, FSE Companion ’25, p.1254–1255. Available from: https://doi.org/10.1145/3696630.3731439. DOI: https://doi.org/10.1145/3696630.3731439
Xia, H., Yang, Z., Dong, Q., Wang, P., Li, Y., Ge, T., Liu, T., Li, W. and Sui, Z., 2024. Unlocking Efficiency in Large Language Model Inference: A Comprehensive Survey of Speculative Decoding. In: L.W. Ku, A. Martins and V. Srikumar, eds. Findings of the Association for Computational Linguistics: ACL 2024. Bangkok, Thailand: Association for Computational Linguistics, pp.7655–7671. Available from: https://doi.org/10.18653/v1/2024.findings-acl.456. DOI: https://doi.org/10.18653/v1/2024.findings-acl.456
Xiao, G., Lin, J., Seznec, M., Wu, H., Demouth, J. and Han, S., 2023. SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models. In: A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato and J. Scarlett, eds. Proceedings of the 40th International Conference on Machine Learning. PMLR, Proceedings of Machine Learning Research, vol. 202, pp.38087–38099. Available from: https://proceedings.mlr.press/v202/xiao23c.html.
Xie, Q., Zhang, H., Wang, M., Wu, W. and Sun, Z., 2024. Privacy-Enhanced Federated Learning Through Homomorphic Encryption With Cloud Federation. 2024 IEEE International Symposium on Parallel and Distributed Processing with Applications (ISPA). pp.1088–1095. Available from: https://doi.org/10.1109/ISPA63168.2024.00144. DOI: https://doi.org/10.1109/ISPA63168.2024.00144
Xu, C., Hou, X., Liu, J., Li, C., Huang, T., Zhu, X., Niu, M., Sun, L., Tang, P., Xu, T., Cheng, K.T. and Guo, M., 2023. MMBench: Benchmarking End-to-End Multi-modal DNNs and Understanding Their Hardware-Software Implications. Proceedings - 2023 IEEE International Symposium on Workload Characterization, IISWC 2023. Institute of Electrical and Electronics Engineers Inc., pp.154–166. Available from: https://doi.org/10.1109/IISWC59245.2023.00014. DOI: https://doi.org/10.1109/IISWC59245.2023.00014
Xu, M., Niyato, D. and Brinton, C.G., 2025. Serving Long-Context LLMs at the Mobile Edge: Test-Time Reinforcement Learning-based Model Caching and Inference Offloading. CoRR, abs/2501.14205. 2501.14205, Available from: https://doi.org/10.48550/ARXIV.2501.14205.
Yan, X. and Ding, Y., 2025. Are We There Yet? A Measurement Study of Efficiency for LLM Applications on Mobile Devices. Proceedings of the 2nd International Workshop on Foundation Models for Cyber-Physical Systems & Internet of Things. New York, NY, USA: Association for Computing Machinery, FMSys, p.19–24. Available from: https://doi.org/10.1145/3722565.3727192. DOI: https://doi.org/10.1145/3722565.3727192
Yang, M., Yang, Y. and Jiang, P., 2024. A design method for edge–cloud collaborative product service system: a dynamic event-state knowledge graph-based approach with real case study. International Journal of Production Research, 62(7), pp.2584–2605. Available from: https://doi.org/10.1080/00207543.2023.2219345. DOI: https://doi.org/10.1080/00207543.2023.2219345
Yang, T., Li, D., Song, Z., Zhao, Y., Liu, F., Wang, Z., He, Z. and Jiang, L., 2022. DTQAtten: Leveraging Dynamic Token-based Quantization for Efficient Attention Architecture. In: C. Bolchini, I. Verbauwhede and I. Vatajelu, eds. Proceedings of the 2022 Design, Automation and Test in Europe Conference and Exhibition, DATE 2022. Institute of Electrical and Electronics Engineers Inc., pp.700–705. Available from: https://doi.org/10.23919/DATE54114.2022.9774692. DOI: https://doi.org/10.23919/DATE54114.2022.9774692
Yang, T., Ma, F., Li, X., Liu, F., Zhao, Y., He, Z. and Jiang, L., 2023. DTA-Trans: Leveraging Dynamic Token-Based Quantization With Accuracy Compensation Mechanism for Efficient Transformer Architecture. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 42(2), pp.509–520. Available from: https://doi.org/10.1109/TCAD.2022.3181541. DOI: https://doi.org/10.1109/TCAD.2022.3181541
Yang, Y., Huang, X. and Sang, J., 2025. Exploring the Privacy Protection Capabilities of Chinese Large Language Models. IEEE Multimedia, 32(2), pp.9–21. Available from: https://doi.org/10.1109/MMUL.2025.3542508. DOI: https://doi.org/10.1109/MMUL.2025.3542508
Yang, Y., Muhtar, D., Shen, Y., Zhan, Y., Liu, J., Wang, Y., Sun, H., Deng, W., Sun, F., Zhang, Q., Chen, W. and Tong, Y., 2025. MTL-LoRA: Low-Rank Adaptation for Multi-Task Learning. Proceedings of the AAAI Conference on Artificial Intelligence, 39(20), pp.22010–22018. Available from: https://doi.org/10.1609/aaai.v39i20.35509. DOI: https://doi.org/10.1609/aaai.v39i20.35509
Yang, Y., Zhou, J., Wong, N. and Zhang, Z., 2024. LoRETTA: Low-Rank Economic Tensor-Train Adaptation for Ultra-Low-Parameter Fine-Tuning of Large Language Models. In: K. Duh, H. Gomez and S. Bethard, eds. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). Mexico City, Mexico: Association for Computational Linguistics, pp.3161–3176. Available from: https://doi.org/10.18653/v1/2024.naacl-long.174. DOI: https://doi.org/10.18653/v1/2024.naacl-long.174
Yao, K., Gao, P., Li, L., Zhao, Y., Wang, X., Wang, W. and Zhu, J., 2024. Layer-wise Importance Matters: Less Memory for Better Performance in Parameter-efficient Fine-tuning of Large Language Models. In: Y. Al-Onaizan, M. Bansal and Y.N. Chen, eds. Findings of the Association for Computational Linguistics: EMNLP 2024. Miami, Florida, USA: Association for Computational Linguistics, pp.1977–1992. Available from: https://doi.org/10.18653/v1/2024.findings-emnlp.109. DOI: https://doi.org/10.18653/v1/2024.findings-emnlp.109
Yao, K., Tan, Z., Ye, T., Li, L., Zhao, Y., Liu, W., Wang, W. and Zhu, J., 2025. ScaleOT: Privacy-utility-scalable Offsite-tuning with Dynamic LayerReplace and Selective Rank Compression. Proceedings of the AAAI Conference on Artificial Intelligence, 39(21), pp.22074–22082. Available from: https://doi.org/10.1609/aaai.v39i21.34360. DOI: https://doi.org/10.1609/aaai.v39i21.34360
Yao, Y., Jin, H., Shah, A.D., Han, S., Hu, Z., Stripelis, D., Ran, Y., Xu, Z., Avestimehr, S. and He, C., 2024. ScaleLLM: A Resource-Frugal LLM Serving Framework by Optimizing End-to-End Efficiency. In: F. Dernoncourt, D. Preoţiuc-Pietro and A. Shimorina, eds. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track. Miami, Florida, US: Association for Computational Linguistics, pp.279–289. Available from: https://doi.org/10.18653/v1/2024.emnlp-industry.22. DOI: https://doi.org/10.18653/v1/2024.emnlp-industry.22
Yao, Y., Li, Z. and Zhao, H., 2024. GKT: A Novel Guidance-Based Knowledge Transfer Framework For Efficient Cloud-edge Collaboration LLM Deployment. In: L.W. Ku, A. Martins and V. Srikumar, eds. Proceedings of the Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics (ACL), pp.3433–3446. DOI: https://doi.org/10.18653/v1/2024.findings-acl.204
Yao, Y., Yu, T., Zhang, A., Wang, C., Cui, J., Zhu, H., Cai, T., Chen, C., Li, H., Zhao, W., He, Z., Chen, Q., Zhou, R., Zou, Z., Zhang, H., Hu, S., Zheng, Z., Zhou, J., Cai, J., Han, X., Zeng, G., Li, D., Liu, Z. and Sun, M., 2025. Efficient GPT-4V level multimodal large language model for deployment on edge devices. Nature Communications, 16(1), p.5509. Available from: https://doi.org/10.1038/s41467-025-61040-5. DOI: https://doi.org/10.1038/s41467-025-61040-5
Yao, Z., Tang, Z., Lou, J., Shen, P. and Jia, W., 2024. VELO: A Vector Database-Assisted Cloud-Edge Collaborative LLM QoS Optimization Framework. In: R.N. Chang, C.K. Chang, Z. Jiang, J. Yang, Z. Jin, M. Sheng, J. Fan, K.K. Fletcher, Q. He, Q. He, C. Ardagna, J. Yang, J. Yin, Z. Wang, A. Beheshti, S. Russo, N. Atukorala, J. Wu, P.S. Yu, H. Ludwig, S. Reiff-Marganiec, E. Zhang, A. Sailer, N. Bena, K. Li, Y. Watanabe, T. Zhao, S. Wang, Z. Tu, Y. Wang and K. Wei, eds. Proceedings of the IEEE International Conference on Web Services, ICWS. Institute of Electrical and Electronics Engineers Inc., pp.865–876. Available from: https://doi.org/10.1109/ICWS62655.2024.00105. DOI: https://doi.org/10.1109/ICWS62655.2024.00105
Ye, S., Ouyang, B., Zeng, L., Qian, T., Chu, X., Tang, J. and Chen, X., 2025. Jupiter: Fast and Resource-Efficient Collaborative Inference of Generative LLMs on Edge Devices. IEEE INFOCOM 2025 - IEEE Conference on Computer Communications. Available from: https://doi.org/10.1109/INFOCOM55648.2025.11044734. DOI: https://doi.org/10.1109/INFOCOM55648.2025.11044734
Yi, H., Lin, F., Li, H., Peiyang, N., Yu, X. and Xiao, R., 2024. Generation Meets Verification: Accelerating Large Language Model Inference with Smart Parallel Auto-Correct Decoding. In: L.W. Ku, A. Martins and V. Srikumar, eds. Findings of the Association for Computational Linguistics: ACL 2024. Bangkok, Thailand: Association for Computational Linguistics, pp.5285–5299. Available from: https://doi.org/10.18653/v1/2024.findings-acl.313. DOI: https://doi.org/10.18653/v1/2024.findings-acl.313
Yokotsuji, R., Lin, D. and Uwano, F., 2024. LLM-Based Interoperable IoT Service Platform. 2024 IEEE/WIC International Conference on Web Intelligence and Intelligent Agent Technology (WI-IAT). pp.438–444. Available from: https://doi.org/10.1109/WI-IAT62293.2024.00070. DOI: https://doi.org/10.1109/WI-IAT62293.2024.00070
Yu, Z., Liang, S., Ma, T., Cai, Y., Nan, Z., Huang, D., Song, X., Hao, Y., Zhang, J., Zhi, T., Zhao, Y., Du, Z., Hu, X., Guo, Q. and Chen, T., 2024. Cambricon-LLM: A Chiplet-Based Hybrid Architecture for On-Device Inference of 70B LLM. Proceedings of the Annual International Symposium on Microarchitecture, MICRO. IEEE Computer Society, pp.1474–1488. Available from: https://doi.org/10.1109/MICRO61859.2024.00108. DOI: https://doi.org/10.1109/MICRO61859.2024.00108
Yu, Z., Wang, Z., Li, Y., Gao, R., Zhou, X., Bommu, S.R., Zhao, Y.K. and Lin, Y.C., 2024. EDGE-LLM: Enabling Efficient Large Language Model Adaptation on Edge Devices via Unified Compression and Adaptive Layer Voting. Proceedings of the 61st ACM/IEEE Design Automation Conference. New York, NY, USA: Association for Computing Machinery, DAC ’24, p.327. Available from: https://doi.org/10.1145/3649329.3658473. DOI: https://doi.org/10.1145/3649329.3658473
Yu, Z., Wu, S., Jiang, J. and Liu, D., 2024. A knowledge-graph based text summarization scheme for mobile edge computing. J. Cloud Comput., 13(1), p.9. Available from: https://doi.org/10.1186/S13677-023-00585-6. DOI: https://doi.org/10.1186/s13677-023-00585-6
Yue, Z., Xiang, X., Wang, Y., Guo, R., Han, H., Wei, S., Hu, Y. and Yin, S., 2025. 14.4 A 51.6TFLOPs/W Full-Datapath CIM Macro Approaching Sparsity Bound and <2-30 Loss for Compound AI. 2025 IEEE International Solid-State Circuits Conference (ISSCC). vol. 68, pp.1–3. Available from: https://doi.org/10.1109/ISSCC49661.2025.10904702. DOI: https://doi.org/10.1109/ISSCC49661.2025.10904702
Zahorodko, P.V., Modlo, Y.O., Kalinichenko, O.O., Selivanova, T.V. and Semerikov, S.O., 2020. Quantum enhanced machine learning: An overview. In: A.E. Kiv, S.O. Semerikov, V.N. Soloviev and A.M. Striuk, eds. Proceedings of the 3rd Workshop for Young Scientists in Computer Science & Software Engineering (CS&SE@SW 2020), Kryvyi Rih, Ukraine, November 27, 2020. CEUR-WS.org, CEUR Workshop Proceedings, vol. 2832, pp.94–103. Available from: https://ceur-ws.org/Vol-2832/paper13.pdf.
Zhang, B., Tian, Y., Wang, S., Tu, Z., Chu, D. and Shen, Z., 2024. GongBu: Easily Fine-tuning LLMs for Domain-specific Adaptation. Proceedings of the 33rd ACM International Conference on Information and Knowledge Management. New York, NY, USA: Association for Computing Machinery, CIKM ’24, p.5309–5313. Available from: https://doi.org/10.1145/3627673.3679233. DOI: https://doi.org/10.1145/3627673.3679233
Zhang, D. and Shi, W., 2024. Blockchain-based Edge Intelligence Enabled by AI Large Models for Future Internet of Things. 2024 IEEE 12th International Conference on Information and Communication Networks, ICICN 2024. Institute of Electrical and Electronics Engineers Inc., pp.368–374. Available from: https://doi.org/10.1109/ICICN62625.2024.10761527. DOI: https://doi.org/10.1109/ICICN62625.2024.10761527
Zhang, L., Li, B., Thekumparampil, K.K., Oh, S. and He, N., 2024. DPZero: private fine-tuning of language models without backpropagation. Proceedings of the 41st International Conference on Machine Learning. JMLR.org, ICML’24, p.2446.
Zhang, M., Shen, X., Cao, J., Cui, Z. and Jiang, S., 2024. EdgeShard: Efficient LLM Inference via Collaborative Edge Computing. IEEE Internet of Things Journal. Available from: https://doi.org/10.1109/JIOT.2024.3524255. DOI: https://doi.org/10.1109/JIOT.2024.3524255
Zhang, S., 2025. Model collaboration framework design for space-air-ground integrated networks. Computer Networks, 257, p.111013. Available from: https://doi.org/10.1016/j.comnet.2024.111013. DOI: https://doi.org/10.1016/j.comnet.2024.111013
Zhang, S., Ma, Y., Fang, L., Jia, H., D’Alfonso, S. and Kostakos, V., 2024. Enabling On-Device LLMs Personalization with Smartphone Sensing. Companion of the 2024 on ACM International Joint Conference on Pervasive and Ubiquitous Computing. New York, NY, USA: Association for Computing Machinery, UbiComp ’24, p.186–190. Available from: https://doi.org/10.1145/3675094.3677545. DOI: https://doi.org/10.1145/3675094.3677545
Zhang, T., Xu, X., Wang, Y., Peng, R. and Kadoch, M., 2025. Optimizing Remote Medical Services with AloT: Integration of Large Language Models and 6G Edge Computing. In: M. Kadoch, M. Cheriet and X. Qiu, eds. Information Processing and Network Provisioning. Singapore: Springer Nature Singapore, Communications in Computer and Information Science, vol. 2416, pp.278–294. Available from: https://doi.org/10.1007/978-981-96-6468-9_25. DOI: https://doi.org/10.1007/978-981-96-6468-9_25
Zhang, Z., Liu, Z., Tian, Y., Khaitan, H., Wang, Z. and Li, S., 2025. R-Sparse: Rank-Aware Activation Sparsity for Efficient LLM Inference. 13th International Conference on Learning Representations, ICLR 2025. pp.17497–17511. Available from: https://openreview.net/forum?id=VpInEFjoLa.
Zhao, J., Song, Y., Liu, S., Harris, I.G. and Abdu Jyothi, S., 2024. LinguaLinked: Distributed Large Language Model Inference on Mobile Devices. In: Y. Cao, Y. Feng and D. Xiong, eds. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations). Bangkok, Thailand: Association for Computational Linguistics, pp.160–171. Available from: https://doi.org/10.18653/v1/2024.acl-demos.16. DOI: https://doi.org/10.18653/v1/2024.acl-demos.16
Zhao, W., Jing, W., Lu, Z. and Wen, X., 2024. Edge and Terminal Cooperation Enabled LLM Deployment Optimization in Wireless Network. International Conference on Communications in China, ICCC Workshops 2024. Institute of Electrical and Electronics Engineers Inc., pp.220–225. Available from: https://doi.org/10.1109/ICCCWorkshops62562.2024.10693742. DOI: https://doi.org/10.1109/ICCCWorkshops62562.2024.10693742
Zhao, W., Zou, L., Wang, Z., Yao, X. and Yu, B., 2025. HAPE: Hardware-Aware LLM Pruning For Efficient On-Device Inference Optimization. ACM Transactions on Design Automation of Electronic Systems, 30(4), p.61. Available from: https://doi.org/10.1145/3744244. DOI: https://doi.org/10.1145/3744244
Zheng, Y., Chen, Y., Qian, B., Shi, X., Shu, Y. and Chen, J., 2025. A Review on Edge Large Language Models: Design, Execution, and Applications. ACM Computing Surveys, 57(8), p.209. Available from: https://doi.org/10.1145/3719664. DOI: https://doi.org/10.1145/3719664
Zhong, S., Yang, Z., Gong, R., Wang, R., Huang, R. and Li, M., 2025. ProPD: Dynamic Token Tree Pruning and Generation for LLM Parallel Decoding. Proceedings of the 43rd IEEE/ACM International Conference on Computer-Aided Design. New York, NY, USA: Association for Computing Machinery, ICCAD ’24, p.202. Available from: https://doi.org/10.1145/3676536.3676695. DOI: https://doi.org/10.1145/3676536.3676695
Zhou, X., Jia, Q., Hu, Y., Xie, R., Huang, T. and Yu, F.R., 2024. GenG: An LLM-Based Generic Time Series Data Generation Approach for Edge Intelligence via Cross-Domain Collaboration. IEEE INFOCOM 2024 - IEEE Conference on Computer Communications Workshops, INFOCOM WKSHPS 2024. Institute of Electrical and Electronics Engineers Inc., pp.1–6. Available from: https://doi.org/10.1109/INFOCOMWKSHPS61880.2024.10620716. DOI: https://doi.org/10.1109/INFOCOMWKSHPS61880.2024.10620716
Zhu, F., Huang, F., Yu, Y., Liu, G. and Huang, T., 2025. Task Offloading with LLM-Enhanced Multi-Agent Reinforcement Learning in UAV-Assisted Edge Computing. Sensors, 25(1), p.175. Available from: https://doi.org/10.3390/s25010175. DOI: https://doi.org/10.3390/s25010175